當檔案上傳遇上高併發:三個問題與解決方案
前言
一個項目有坑的狀況:單一用戶「單檔上傳」運作正常的功能,改成「一次上傳 3 個檔案(圖片+影片)」後,伺服器直接 Memory 溢出!本文將分享如何一步步分析原因為何。
系統背景
在開始之前,先了解一下我們現有的系統架構:
| 項目 | 說明 |
|---|---|
| 技術棧 | FuelPHP |
| Web Server | 4 台 Apache(Load Balancer 分流) |
| 資料庫 | MySQL 讀寫分離(2 台) |
| 圖片處理 | PHP GD Library |
原本的功能: 用戶每次在前端上傳「一張圖片」或「一個影片」的功能
新需求: 改成一次可上傳「3 個檔案」(圖片+影片任意組合)
情境沙雕動畫
情境影片,歡迎輕鬆觀閱!
問題一:Server 的 Memory 溢出
當一個 Request 同時處理多張圖片時,PHP 使用 GD 壓縮圖片將佔用大量記憶體,導致 Memory 溢出。
為什麼會 Memory 溢出?
PHP GD 處理圖片時,會將整張圖片解壓縮後載入記憶體(不是檔案大小!)。
根據 PHP 官方手冊 提供的記憶體計算公式:
1 | // PHP Manual 建議的記憶體估算公式(處理圖片需要把圖片「完整的解壓縮」到記憶體,所以記憶體佔用的容量遠大於 Disk 儲存的檔案大小)。 |
| 參數 | 說明 |
|---|---|
width * height | 圖片像素總數 |
bits | 色彩深度(通常 8 bits) |
channels | 色彩通道數(RGB=3, RGBA=4) |
65536 (64KB) | GD 內部額外開銷 |
1.65 | 經驗調整係數(Tweak Factor) |
實際計算範例
以一張 4000 x 3000 的 24-bit JPG 圖片為例:
1 | 基礎記憶體:4000 × 3000 × 8 × 3 / 8 = 36,000,000 bytes ≈ 34.3 MB |
真實案例:根據 Stack Overflow 討論,有開發者回報一張 1.8 MB 的 JPG 檔案,實際處理時佔用了 85 MB 記憶體!這是因為高壓縮率的圖片解壓後會膨脹數十倍。
壓縮過程的記憶體消耗
當使用 imagecopyresampled() 進行縮放時,需要同時載入原圖和目標圖:
1 | 原圖(4000×3000):≈ 57 MB |
這就是為什麼 memory_limit = 128M 在處理多張大圖時會直接爆掉!而且檔案大小(如 2MB)完全無法反映真實的記憶體需求。
解法 A:緊急止血(開發時間 1-2 天)
調整 PHP 設定 + 前端壓縮
1 | ; (第一種方式)php.ini(或者在程式內部 Hard-coding 設定) |
1 | # (第二種方式)程式內動態調整記憶體上限(參考以下 PHP 官方文件提供的設定) |
搭配前端先壓縮再上傳:
1 | // 使用 browser-image-compression |
優點:快速讓功能運作
缺點:治標不治本,規格一變就要重調上限大小,或者單一worker佔用過多資源,導致 Server 效率被拖累
拆分 Request
將「一次傳 3 個檔案」改為「發送 3 個獨立的 Request」:
1 | 原本:1 Request → 3 個檔案 → 1 個 Worker 處理全部 |
為什麼更好?
| 優勢 | 說明 |
|---|---|
| 善用 Load Balancer | 3 個 Request 可分散到不同 Server |
| 記憶體壓力降低 | 每個 Worker 只處理 1 個檔案 |
| 過往功能正常 | 過往單一檔案上傳並沒有出現任何問題,代表業務上OK,這樣的調整方案,風險更低 |
優點:充分利用現有架構,改動最小,也能最快上線同時風險低
缺點:消耗更多連接數(更多的 Process),對於高併發承受力低
解法 B:架構重構(長期方案)
核心思路:把「圖片處理」從 Web Server(不在 PHP GD 中處理) 中抽離出來!
1 | 原本架構: |
S3 Presigned URL 範例:
1 | use Aws\S3\S3Client; |
優點:(微服務)Web Server 不再處理檔案 I/O,讓 Lambd 來處理
優點:可用更適合的語言處理圖片(Python、Go),利於效能與擴充
- Go:效能更佳,使用 bimg 套件切片處理圖片,不需「Tweak Factor」,即使 8K 圖片也能確保記憶體用量僅 5MB~10MB
- Python:擴充性更強,未來若需圖片「辨識」、「去噪」或「畫質修復」,可使用 PyTorch 等套件
問題二(延伸):網路上傳緩慢
大檔案 + 不穩定的網路 = 上傳失敗或逾時,用戶需要整個重傳!
解法:切片上傳(Chunked Upload)
將大檔案切成小塊上傳,支援斷點續傳。詳細實作可參考:
注意:Load Balancer 的坑
由於系統有 Load Balancer,切片可能被分散到不同的 Web Server,導致無法合併!
解決方案:使用 S3 作為暫存
1 | 用戶 → 切片上傳 → S3 → 觸發合併 → 處理完成 |
AWS S3 原生支援 Multipart Upload,可以直接利用,不需要自己實作合併邏輯!
補充:切片暫存的清理策略
切片上傳若中途失敗或用戶放棄,會留下未合併的切片佔用儲存空間,務必規劃清理機制!
S3 Lifecycle Rule 自動清理:
S3 可透過 Lifecycle Rule 設定「Abort incomplete multipart uploads」,讓未完成合併的切片在超過指定天數後自動刪除:
1 | { |
優點:完全自動化,無需額外維護
優點:節省儲存成本
Shell Script 定期清理:
如果是使用本地檔案系統作為暫存,需要自行實作清理機制:
1 |
|
搭配 Cron Job 定期執行:
1 | # 每天凌晨 3 點執行清理 |
優點:省成本、快速方便低學習成本
缺點:需要自行維護,可能遺漏邊界情況
缺點:無法像 S3 Lifecycle 那樣精確管理
(額外補充)如果資料庫有上傳資料,那麼會有以下處理
無論使用 S3 或本地暫存,資料庫中的上傳記錄也需要配套處理:
適用場景: 需持續追蹤跟查詢的資料
例如每天要進行用戶分析的場景,資料需要即時可查詢。
優點:查詢速度快,無遷移成本
缺點:資料庫容量持續增長,長期成本高
適用場景: 不需要經常查詢歷史資料(且不追求快速查詢)
例如每個月需要跑 1 次的報表 Job,將資料匯出至 S3,用 Athena 按需查詢(按掃描量計費,類似 BigQuery)。
優點:大幅降低資料庫負擔,查詢成本低
缺點:查詢速度較慢,需額外維護匯出流程
適用場景: 極少存取的歷史資料
適合法規要求保留但幾乎不會查詢的資料,大幅降低儲存成本。
優點:儲存成本極低(約 S3 Standard 的 1/10)
缺點:讀取需等待數分鐘至數小時
適用場景: 無需保留的過期且不具備任何價值的資料
搭配排程任務定期刪除資料,釋放資料庫空間。
優點:徹底釋放空間,無長期成本
缺點:資料刪除後無法復原
優點:慢網也能緩慢上傳直至成功
優點:網路中斷不用整個重傳(因為支援斷點續傳)
缺點:前後端邏輯較複雜
問題三(延伸):(高併發)用戶改為每日可以發 10 篇投稿(投稿=上傳1張圖片)
當需求擴展到「每日 10 篇投稿」時,假設 100 個用戶同時上傳 10 張圖片 = 1,000 張圖片同時處理,現有架構難以承受!
(註:一般商業場景下,最常見的就是兩招就是:提高 Server 數、Server 配置)
先理解:什麼是吞吐量(Throughput)?
吞吐量指的是系統在單位時間內能處理的請求數量,常用 QPS(Queries Per Second) 來衡量。
QPS 計算公式:
1 | QPS = 總請求數 / 總消耗時間(秒) |
實際案例計算:
假設我們的圖片處理服務:
- 處理一張圖片需要 2 秒(含壓縮、儲存)
- 單台 Server 同時只能處理 10 個 PHP Worker
1 | 單台 Server 的 QPS = 10 Workers / 2 秒 = 5(單台 Server 1秒最多處理5張圖片,再多就爆了⚠️) |
問題來了:
1 | 活動開始時,100 個用戶同時上傳 10 張圖片: |
更糟的是,當所有 Worker 都在處理圖片時,其他用戶連一般網頁瀏覽都會受到影響!
解法:Message Queue(MQ)
MQ 能解決三個核心問題:異步、解耦、削峰
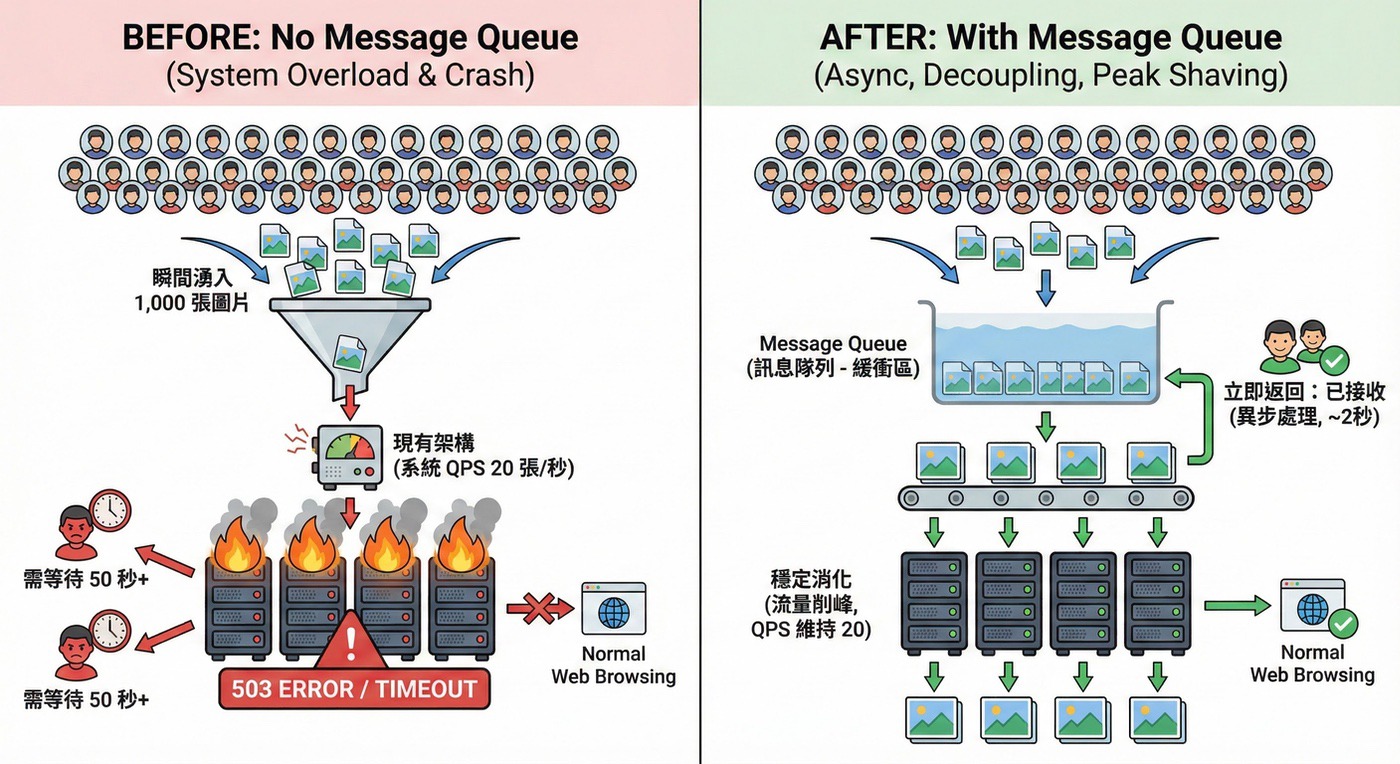
異步處理
用戶上傳完成後立即返回,不需等待處理完成:
1 | Before:用戶等待 → 上傳 → 壓縮 → 浮水印 → 儲存 → 返回(可能 30 秒) |
優點:用戶體驗大幅提升
服務解耦
上傳服務與處理服務分離,互不影響:
1 | Job 進入 MQ 後: |
優點:單一環節失敗不會導致整體失敗
流量削峰
高峰期請求排隊處理,確保系統吞吐量穩定:
1 | 瞬間湧入 1,000 個 Jobs |
對比沒有 MQ 的情況:
| 情境 | 沒有 MQ | 有 MQ |
|---|---|---|
| 系統反應 | 全部 Worker 被佔滿,503 Error | Jobs 排隊,逐步處理 |
| 用戶體驗 | 上傳失敗,需重傳 | 立即返回「處理中」 |
| 其他功能 | 網站無法瀏覽 | 正常運作 |
| 吞吐量 | 超載後歸零 | 維持穩定 20 QPS |
優點:系統穩定性大幅提升
優點:吞吐量維持穩定,不會因超載而崩潰
MQ 選型建議
通用 MQ 服務:
| 選項 | 適用場景 |
|---|---|
| AWS SQS | 已使用 AWS 生態系,免維護 |
| Redis Queue | 需要高效能、低延遲 |
| RabbitMQ | 需要複雜的路由規則 |
| Beanstalkd | 簡單輕量、PHP 友善 |
PHP 框架是否支援 MQ:
| 框架 | MQ 支援 | 說明 |
|---|---|---|
| Laravel | 內建完整支援 | 支援 Database、Redis、SQS、Beanstalkd 等多種 Driver,搭配 Horizon 可視覺化管理 |
| FuelPHP | 需安裝套件 | 可使用 fuel-jobqueue(搭配 Beanstalkd)或 fuelphp-queue;若不需即時處理,也可透過內建 Tasks + Cron 模擬異步任務(非 MQ,但可達成類似效果) |
| Hyperf | 內建完整支援 | 基於 Swoole 協程,原生支援 Redis、AMQP、Kafka 等,效能極高,適合微服務 |
| Swoole | 需自行實作 | PHP C 擴展,可搭配 Redis 或其他 MQ 服務自行實作 |
| ReactPHP | 需安裝套件 | 事件驅動架構,可搭配 react/async 實現異步任務 |
| Laravel Hyperf | 內建完整支援 | Laravel 風格 + Swoole 協程,MQ 用法與 Laravel 相似 |
最終架構圖
sequenceDiagram
autonumber
box 前端
participant U as 用戶瀏覽器
end
box 後端
participant W as Web Server
participant DB as MySQL
participant Q as MQ
end
box AWS
participant S3 as S3
participant L as Lambda
end
U->>W: 請求上傳(檔案資訊)
W->>DB: 寫入上傳記錄
W->>W: 產生 Presigned URL
W-->>U: 回傳 Presigned URL
U->>S3: 使用 Presigned URL 直傳檔案
S3-->>U: 上傳成功
Note over S3: 若有設計切片上傳,此處需考量切片保留生命週期機能<br/>(eg: S3 Lifecycle Rule, etc.)
U->>W: 通知上傳完成
W->>Q: 發送處理 Job
Q->>L: 觸發圖片處理
L->>S3: 讀取原圖
L->>L: 壓縮/浮水印
L->>S3: 儲存處理後圖片
L->>DB: 更新處理狀態
各角色職責說明:
| 角色 | 負責任務 |
|---|---|
| 前端(用戶瀏覽器) | 請求上傳 → 取得 Presigned URL → 直傳 S3 → 通知後端完成 |
| 後端(Web Server) | 產生 Presigned URL → 寫入 DB → 發送 Job 到 MQ |
| AWS S3 | 接收檔案上傳 → 儲存原圖與處理後圖片 |
| AWS MQ(SQS) | 接收 Job → 觸發 Lambda |
| AWS Lambda | 從 S3 讀取原圖 → 壓縮/加浮水印 → 存回 S3 → 更新 DB 狀態 |
總結
解決方案的選擇取決於:時間壓力、團隊能力、預算。
| 問題 | 緊急解(1-2 天) | 最佳解(1 個月+) |
|---|---|---|
| Memory 溢出 | 拆分 Request、前端壓縮 | 微服務化 + Lambda |
| 網路緩慢 | 增加 timeout | 切片上傳 + S3 |
| 高併發 | 調高 memory_limit | MQ 異步處理 |
延伸閱讀
MQ 概念演示
相關的官方文件