MySQL 讀寫分離:過期讀問題與解決方案全攻略
前言
現實商務環境中,MySQL 讀寫分離是非常常見的架構。但當你寫入資料後立即查詢,卻發現資料「消失」了?這就是經典的「⚠️ 過期讀」問題!本文將深入分析原因與解決方案。
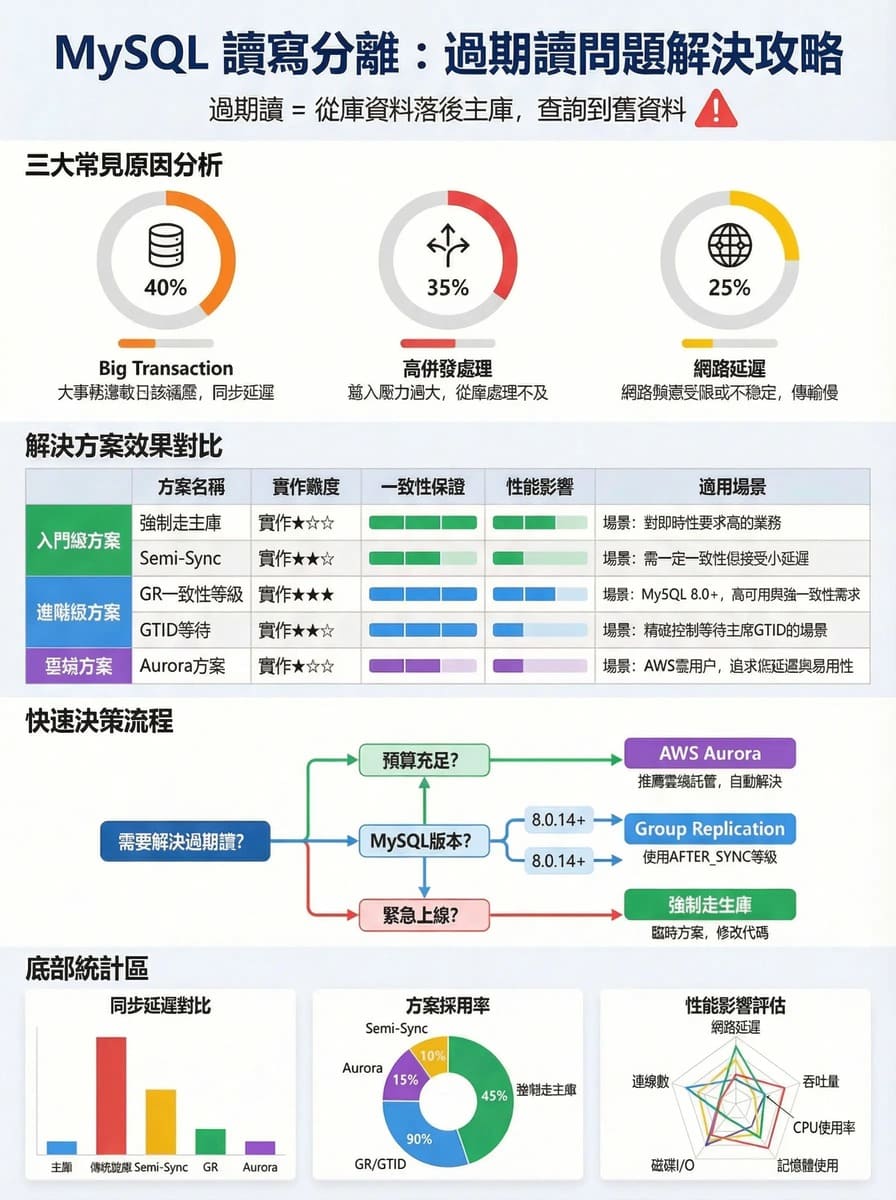
讀寫分離文章重點快速理解一圖流
情境沙雕動畫
歌曲
為什麼採用「一寫多讀」架構?
主流商業環境都採用「一寫多讀」而非「多寫多讀」架構,原因是什麼?
| 架構 | 說明 | 風險 |
|---|---|---|
| 一寫多讀 | 單一主庫負責寫入,多個從庫負責讀取 | 無資料衝突風險,但可能發生過期讀 |
| 多寫多讀 | 多個主庫都可寫入 | 當 Binlog 延遲時,除了過期讀,更會發生資料間的 PK 衝突(如兩邊同時新增 ID=10) |
結論:目前我自己實務經驗中,幾乎接觸到的都是一寫多讀居多,幾乎沒遇過多寫多讀的架構設計,所以這篇文章也主要 針對一寫多讀來進行詳細的技術討論。
(備註:未來如果有特殊案例使用多寫多讀的架構,我將在補充在這篇文章。)
讀寫分離的同步原理
在深入問題之前,先了解讀寫分離的同步流程(以下僅列重點流程,不會將完整的 InnoDB 下的 two-phase commit 都展開):
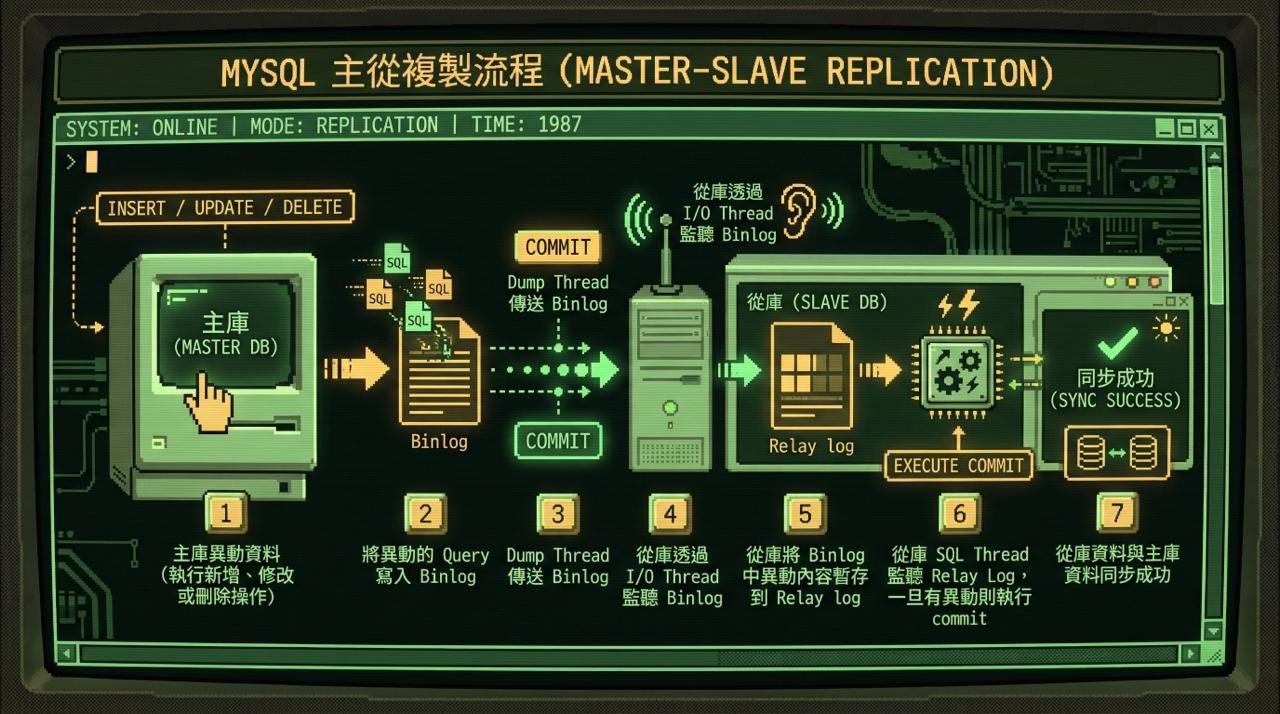
1 | Step 1. 主庫異動資料(執行新增、修改或刪除操作) |
問題:什麼情況會導致「過期讀」?
「過期讀」指的是:從庫的資料尚未與主庫同步,導致查詢到舊資料。
三大常見原因
| 原因 | 說明 |
|---|---|
| Big Transaction | 一次刪除百萬筆資料,主庫 Binlog 快速寫入,但從庫需要較長時間同步 |
| 高併發 | 主庫效能高、從庫較弱時,SQL Threads 需排隊處理 |
| 網路問題 | 跨區部署(如美國↔日本)會有網路延遲 |
監控指標: 在 AWS CloudWatch 可監控 ReplicaLag:
- 數值 = 0:完全同步
- 數值 = 10:從庫資料落後主庫 10 秒
解法一:緊急止血方案
需要快速上線、無法大改架構時的臨時解法。
強制走主庫
直接放棄讀寫分離,所有查詢都走主庫。
優點:最簡單、100% 保證資料一致性
缺點:失去讀寫分離的意義,主庫負擔加重
Sleep 等待
在查詢前加入 Sleep,等待從庫同步完成。
1 | // 寫入後等待 1 秒再查詢 |
優點:實作簡單、適合緊急情況
缺點:不精確、浪費時間,不適合長期的一個方案
延伸:解決 Sleep 不精確的最佳解
Sleep 的問題在於「不精確」——延遲 400ms 時你等了 2 秒是浪費,延遲 2.5 秒時你等 2 秒又不夠。以下是更精確的做法。
查詢同步狀態
1 | -- MySQL 8.0.22+ |
三種判斷方式
| 方式 | 說明 | 精確度 |
|---|---|---|
seconds_behind_master | 查看是否為 0(單位:秒) | ⭐ 低 |
| 對比位點 | 比對 Master_Log_File 與 Relay_Master_Log_File | ⭐⭐ 中 |
| 對比 GTID | 比對 Retrieved_Gtid_Set 與 Executed_Gtid_Set | ⭐⭐⭐ 高 |
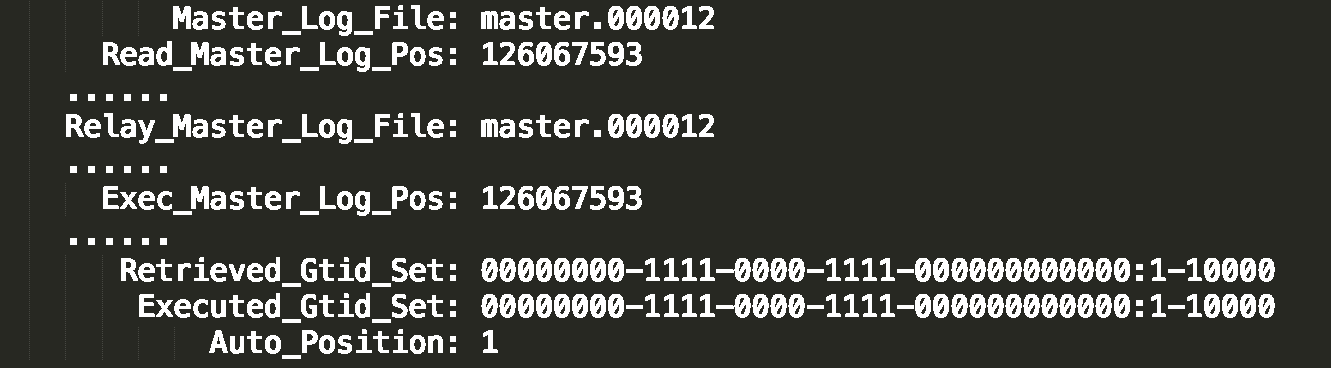
seconds_behind_master 的盲點
重要: seconds_behind_master = 0 不代表主從資料一定同步!
這個指標只能反映從庫 SQL Thread 的執行進度,無法偵測主從連線中斷的情況。
當主從連線中斷時,從庫的 I/O Thread 停止接收 Binlog,但 SQL Thread 會繼續執行 Relay Log 中的內容。一旦 Relay Log 全部執行完畢,seconds_behind_master 就會顯示 0,但實際上從庫已經與主庫脫節了。
斷線情境分析
根據斷線發生的時間點,會產生不同的資料狀態:
1 | 【主庫 Master】 |
| 斷線點 | 主庫狀態 | 從庫狀態 | 資料一致性 | 說明 |
|---|---|---|---|---|
| A:寫入 Binlog 前 | 無資料(Rollback) | 無資料 | ✅ 一致 | 交易尚未完成,主從都沒有這筆資料 |
| B:Binlog 寫入後、傳送前 | 有資料 | 無資料 | ❌ 不一致 | 主庫已 Commit,但 Binlog 尚未傳送給從庫 |
| C:Binlog 傳送中 | 有資料 | 可能有/無資料 | ❓ 不確定 | 取決於從庫是否成功接收並執行 |
關鍵問題:斷線點 B 和 C 發生時,seconds_behind_master 仍可能顯示 0,但資料已經不一致!
建議檢查策略
僅依賴 seconds_behind_master 是不夠的,應搭配其他指標綜合判斷:
1 | -- 完整檢查從庫狀態(MySQL 8.0+) |
| 欄位 | 檢查目的 | 正常狀態 |
|---|---|---|
Replica_IO_Running | I/O Thread 是否運作中 | Yes |
Replica_SQL_Running | SQL Thread 是否運作中 | Yes |
Seconds_Behind_Source | 延遲秒數 | 0 或接近 0 |
Last_IO_Error | I/O Thread 錯誤訊息 | 空白 |
Last_SQL_Error | SQL Thread 錯誤訊息 | 空白 |
核心檢查邏輯:
- 先確認
Replica_IO_Running = Yes:確保 I/O Thread 正在運作並持續接收 Binlog - 再確認
Replica_SQL_Running = Yes:確保 SQL Thread 正在執行 Relay Log - 最後檢查
Seconds_Behind_Source:確認執行進度
如果 Replica_IO_Running = No,無論 Seconds_Behind_Source 顯示多少,主從同步都已中斷!
(延伸詢問)如果 Binlog 這麼多問題,不開啟 Binlog 就好啦,不是嗎?
很顯然,這是不可行的!因為一一
沒有 Binlog 就無法進行主從複製!
Binlog 是主從同步的基礎,若未開啟則整個複製機制無法運作。
| 功能 | Binlog 開啟 | Binlog 關閉 |
|---|---|---|
| 主從複製 | ✅ 正常運作 | ❌ 完全無法運作 |
| 讀寫分離 | ✅ 可實現 | ❌ 無法實現 |
| 資料恢復(Point-in-Time Recovery) | ✅ 可恢復到任意時間點 | ❌ 只能恢復到最近一次完整備份 |
| 資料審計 | ✅ 可追溯所有變更 | ❌ 無法追溯 |
檢查 Binlog 是否開啟:
1 | -- 檢查 Binlog 狀態 |
生產環境必須開啟 Binlog!
如果你的環境需要主從複製、讀寫分離或災難恢復能力,Binlog 是必要條件。
(延伸詢問)如果不開啟 Binlog 就無法主從複製、讀寫分離、資料恢復等,那麼我使用 AWS Aurora 服務,Binlog 就沒打開過呀!你在騙我沒讀過書嗎?
這題問的非常的 Good,其實呢一一
Aurora 的主從同步不依賴 Binlog!
Aurora 採用完全不同的架構,透過共享儲存層實現資料同步,而非傳統的 Binlog 複製。(其它雲服務沒研究,之後有研究再來補上,eg:GCP、Azure 等)
傳統 MySQL vs Aurora 架構對比:
1 | 【傳統 MySQL 主從複製】 |
| 項目 | 傳統 MySQL | AWS Aurora |
|---|---|---|
| 同步機制 | Binlog 複製 | 共享儲存層 |
| 同步延遲 | 通常數10ms~秒 | 通常 < 100ms |
| Binlog 用途 | 主從同步必要 | 僅用於外部複製(如複製到其他 Region) |
| 過期讀問題 | 較常見 | 較少,但仍可能發生 |
Aurora 的 Binlog 使用場景:
1 | -- 檢查 Aurora 的 Binlog 狀態 |
| Aurora Binlog 狀態 | 說明 |
|---|---|
| OFF(預設) | Aurora 叢集內的 Reader 同步正常運作,無需 Binlog |
| ON | 需要將資料複製到 Aurora 叢集外部時才開啟(如跨 Region 複製、複製到自建 MySQL) |
結論:
- 傳統 MySQL:沒有 Binlog = 無法主從同步
- AWS Aurora:沒有 Binlog = 叢集內同步正常,只是無法複製到外部
對比位點詳解
1 | Master_Log_File 和 Read_Master_Log_Pos:讀到的主庫最新位點 |
使用前提: 對比位點是 MySQL 傳統的複製方式,所有版本預設支援,無需額外設定。
對比 GTID 詳解
1 | Auto_Position=1:表示使用 GTID 協議 |
使用前提: GTID 需要手動啟用
檢查是否已啟用 GTID:
1 | SHOW GLOBAL VARIABLES LIKE 'gtid_mode'; |
- 結果為
ON:已啟用,可使用 GTID 對比 - 結果為
OFF:未啟用,請使用對比位點方式
推薦: 對比位點和 GTID 比判斷 seconds_behind_master 更精確。
解法二:MySQL 8.0+ 主流解法
MySQL 8.0.14+ 在 Group Replication (GR) 模式下提供 group_replication_consistency 參數,讓資料庫自動處理同步等待,無需應用層實作。注意:這適用於GR,Standard Source-Replica 架構是不支援以下參數。
(GR 要有設定啟用才可以,使用 「SELECT * FROM performance_schema.replication_group_members;」 來確認自己的 Mysql 是否有 GR。)
參數說明
| 參數值 | 行為 | 適用場景 |
|---|---|---|
EVENTUAL | (預設)不等待,直接執行 | 重視效能,可容忍舊資料 |
BEFORE_ON_PRIMARY_FAILOVER | 只在主庫切換時等待 | 防止切換時讀錯資料 |
BEFORE | 執行前等待此節點追上所有更新 | 從庫使用,確保不讀舊資料 |
AFTER | 寫入後等待其他節點套用完成 | 主庫使用,確保寫入後全局可見 |
從庫使用範例(BEFORE)
1 | -- 連線到從庫 |
主庫使用範例(AFTER)
1 | -- 連線到主庫 |
解法三:AWS Aurora 專用方案
使用 AWS Aurora 時,有專屬的解決方案(Aurora 不使用 group_replication_consistency)。
使用 replica_host_status 監控
查詢各從庫的延遲狀況,選擇延遲最低的從庫:
1 | SELECT * FROM information_schema.replica_host_status; |
策略:
- 選擇延遲最低的從庫查詢
- 若所有從庫延遲都很高,則直接查主庫
優點:毫秒級延遲監控(比傳統 MySQL 秒級更精確)
缺點:需要應用層實作選擇邏輯
使用 aurora_replica_read_consistency
名詞解釋: LSN (Log Sequence Number) 是日誌序列號,用於追蹤資料庫變更進度,Aurora 透過 LSN 確保從庫與主庫的同步狀態
檢查當前設定:
1 | -- 查詢當前 Session 的設定 |
設定值說明:
''(空值):預設值,不等待同步session:等待當前 Session 的寫入同步global:等待所有寫入同步(最嚴格)
使用範例:
1 | -- 設定強制全局一致性 |
優點:Aurora 原生支援,實作簡單
缺點:增加查詢延遲
進階議題:資料保護機制(斷電、特殊情況處理)
情境: 你剛下了一筆訂單,系統回覆「下單成功」,但主庫突然掛了!當系統切換到備用資料庫(從庫)時,如何確保你的訂單不消失?(沒有特別設定的話,一般都是異步複製,具體可以查閱參考下圖)
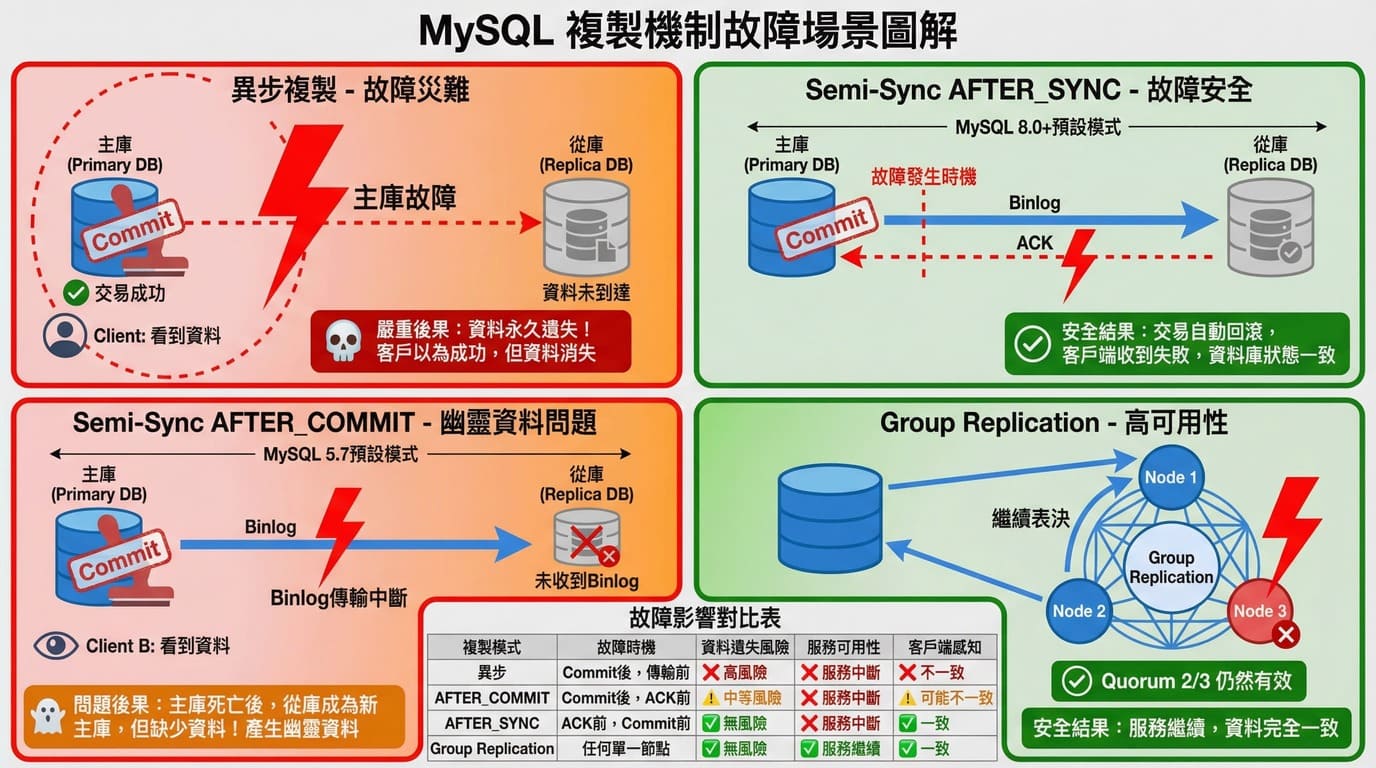
重要: 以下提供兩種解決方案中,預設都是關閉的,需要手動安裝並啟用!
Semi-Sync 半同步複製
確保「客戶端收到成功時,至少一個從庫已經有 Binlog」,保證故障轉移時資料不丟失。
ACK 定義: ACK 是一種「確認訊號(acknowledgement)」,表示收到資料並成功處理過的回應。
Semi-Sync 的核心價值
核心保證: 如果客戶端收到「成功」,至少一個從庫已經有 Binlog,故障轉移時資料不會丟失。
異步複製的問題:寫入者被騙
1 | 【異步複製的問題】 |
核心問題:客戶端收到「成功」,但從庫沒有資料,故障轉移後資料丟失
Semi-Sync 的兩種等待點模式
Semi-Sync 有兩種「等待點」模式,決定主庫何時 Commit:
| MySQL 版本 | 可用模式 | 預設模式 | 說明 |
|---|---|---|---|
| 5.5 ~ 5.6 | 只有 AFTER_COMMIT | AFTER_COMMIT | 解決寫入者問題,但存在 Phantom Data 風險 |
| 5.7 | AFTER_COMMIT AFTER_SYNC | AFTER_COMMIT | 新增 AFTER_SYNC 選項,但預設仍是舊模式 |
| 8.0+ | AFTER_COMMIT AFTER_SYNC | AFTER_SYNC | 預設改為 AFTER_SYNC(無損複製) |
模式一:AFTER_COMMIT(5.5 ~ 5.6 唯一選項)
流程:
1 | 主庫寫 Binlog → 主庫 Commit(資料落地)→ 傳給從庫 → 等待 ACK → 回覆客戶端 |
正常情況:解決了寫入者問題
1 | 【AFTER_COMMIT 正常流程】 |
優點:客戶端收到「成功」時,從庫一定已有 Binlog,解決了異步複製資料不一致的問題
邊界情況:Phantom Data 風險
⚠️ 關鍵時間點: 只有在「主庫 Commit 後、傳 Binlog 前」的極短時間內斷電,才會產生 Phantom Data!這是 AFTER_COMMIT 模式的致命缺陷。
1 | 【AFTER_COMMIT:主庫傳 Binlog 時掛了】 |
| 角色 | 狀態 |
|---|---|
| 客戶端 A(寫入者) | 收到失敗/超時,知道要重試 |
| 客戶端 B(讀取者) | 曾經看到資料,現在消失了 |
| 舊主庫 | 有這筆資料(Phantom Data) |
| 新主庫(從庫) | 沒有這筆資料 |
風險 1:讀取者看到的資料消失了(Phantom Data),造成讀取者困惑
風險 2:舊主庫修復後會有「幽靈資料」,與新主庫不一致
為什麼 MySQL 5.5/5.6 時代仍然使用 AFTER_COMMIT?
| 對比 | 異步複製 | AFTER_COMMIT |
|---|---|---|
| 寫入者收到「成功」 | 從庫可能沒資料 ❌ | 從庫一定有資料 ✅ |
| 寫入者收到「失敗」 | 從庫可能有資料 ❓ | 從庫可能有資料 ❓ |
| 讀取者風險 | 無額外風險 | 可能看到消失的資料 |
| 核心價值 | 無保證 | 寫入者的承諾被履行 ✅ |
歷史背景: AFTER_COMMIT 的設計優先解決「寫入者信任」問題——確保客戶端收到成功時資料不會丟失。Phantom Data 發生的機率極低(需要在 Commit 後、傳 Binlog 前的毫秒級時間窗口內斷電),對大多數業務場景來說是可接受的折衷。Facebook、阿里巴巴等大公司在 MySQL 5.7 之前都使用過這種模式。
模式二:AFTER_SYNC(5.7 新增,8.0+ 預設)
AFTER_SYNC 解決了「Phantom Data」兩個問題,是真正的「無損複製(Lossless Replication)」。MySQL 8.0 啟用 Semi-Sync 時自動使用此模式。
流程:
1 | 主庫寫 Binlog → 傳給從庫 → 等待 ACK → 主庫 Commit → 回覆客戶端 |
關鍵差異: 先等 ACK,再 Commit。這確保了在任何時間點斷電,都不會有「已 Commit 但從庫沒資料」的情況。
場景一:成功收到 ACK(正常流程)
1 | 時間軸: |
| 角色 | 狀態 |
|---|---|
| 客戶端 | 收到「成功」✅ |
| 新主庫(從庫) | 有資料 ✅ |
| 結果 | 承諾被履行,資料不丟失 ✅ |
場景二:主庫傳 Binlog 時掛了(AFTER_SYNC 如何避免 Phantom Data)
關鍵差異: AFTER_SYNC 在「收到 ACK 之前」不會 Commit,確保資料從未對任何人可見。
1 | 【AFTER_SYNC:主庫傳 Binlog 時掛了】 |
| 角色 | 狀態 |
|---|---|
| 客戶端 A(寫入者) | 收到「失敗」❌ |
| 客戶端 B(讀取者) | 從未看到訂單 #12345 ❌ |
| 舊主庫 | 沒有資料(Rollback) |
| 新主庫(從庫) | 沒有資料 |
| 結果 | 所有人的認知一致,無幽靈資料 ✅ |
關鍵優勢:資料從未 Commit,客戶端 B 根本看不到,避免了 Phantom Data
優點 1:客戶端收到「失敗」= 資料確實不存在,可安全重試
優點 2:舊主庫重啟後會 Rollback,不會有幽靈資料
AFTER_COMMIT vs AFTER_SYNC 完整對比
| 項目 | AFTER_COMMIT | AFTER_SYNC |
|---|---|---|
| 流程順序 | Commit → 傳 Binlog → 等 ACK | 傳 Binlog → 等 ACK → Commit |
| 寫入者收到「成功」 | 從庫一定有資料 ✅ | 從庫一定有資料 ✅ |
| 寫入者收到「失敗」 | 從庫可能有資料 ❓ | 從庫一定沒資料 ✅ |
| Phantom Data 風險 | 有(讀取者可能看到消失的資料) | 無 ✅ |
| 適用版本 | MySQL 5.5+ | MySQL 5.7+ |
| 推薦程度 | 舊版折衷方案 | 推薦使用 ✅ |
如何開啟 Semi-Sync
MySQL 5.5 ~ 5.7 版本:
1 | -- ========== 主庫設定 ========== |
MySQL 8.0+ 版本(名稱變更):
1 | -- ========== 主庫設定 ========== |
名稱變更: MySQL 8.0 將 master/slave 改為 source/replica,舊名稱仍可用但已標記為 deprecated。
檢查 Semi-Sync 狀態
1 | -- 查看 Plugin 是否已安裝 |
關鍵狀態指標:
| 變數 | 說明 |
|---|---|
Rpl_semi_sync_master_status | ON 表示 Semi-Sync 運行中 |
Rpl_semi_sync_master_wait_point | 顯示當前使用的模式(5.7+) |
Rpl_semi_sync_master_clients | 已連線的 Semi-Sync 從庫數量 |
永久生效設定
上述設定重啟後會失效,若要永久生效需寫入 my.cnf:
1 | # 主庫(MySQL 5.7) |
優缺點總結
AFTER_SYNC(MySQL 5.7+ 推薦):
優點 1:確保「客戶端收到成功 = 資料一定在從庫」,故障轉移時不丟失
優點 2:確保「客戶端收到失敗 = 資料確實不存在」,可安全重試
優點 3:無 Phantom Data 風險,所有人的認知一致
優點 4:配置簡單,不需改應用程式
缺點 1:增加寫入延遲(需等待從庫 ACK)
缺點 2:從庫故障時可能退化為異步複製
AFTER_COMMIT(MySQL 5.5/5.6 唯一選項):
優點:確保「客戶端收到成功 = 資料一定在從庫」
缺點 1:存在 Phantom Data 風險(讀取者可能看到消失的資料)
缺點 2:「客戶端收到失敗」時,資料可能已存在
注意: rpl_semi_sync_master_timeout 預設 10,000 ms。若從庫超時(例如從庫掛了),Semi-Sync 會暫時退化為異步複製,此時若主庫也掛了,仍可能造成資料丟失。
重點理解: Semi-Sync 的核心價值是「確保承諾的可靠性」——回覆成功時,資料一定在至少一個節點上。AFTER_SYNC 更進一步確保「回覆失敗時,資料確實不存在」,消除了所有邊界情況的不一致性。
Group Replication
使用 Paxos-like 協議,需要多數節點同意才算真正 Commit,提供更強的資料保護。
流程:
1 | 1. 主庫寫入事件 |
場景一:達成 Quorum(正常流程)
1 | 時間軸: |
| 角色 | 狀態 |
|---|---|
| 客戶端 | 收到「成功」✅ |
| 多數節點 | 都有資料 ✅ |
| 結果 | 自動故障轉移,資料不丟失 ✅ |
場景二:未達成 Quorum
1 | 時間軸: |
| 角色 | 狀態 |
|---|---|
| 客戶端 | 收到「失敗」❌ |
| 所有節點 | 都沒有資料 ❌ |
| 結果 | 狀態一致,客戶端可重試 ✅ |
與 Semi-Sync 的差異:
| 項目 | Semi-Sync | Group Replication |
|---|---|---|
| 確認機制 | 至少 1 個從庫 ACK | 多數節點同意(Quorum) |
| 故障轉移 | 需手動或外部工具 | 自動選主 ✅ |
| 資料保護 | 至少 1 個節點有資料 | 多數節點都有資料 |
| 複雜度 | 低 | 高 |
優點 1:多數節點都有資料,保護更強
優點 2:支援自動故障轉移,無需人工介入
優點 3:避免腦裂問題(透過 Quorum 機制)
缺點 1:架構較複雜,需要至少 3 個節點
缺點 2:寫入延遲較高(需等待多數節點)
實戰場景與策略選擇
以下依照實作難度分類,幫助你快速找到適合的策略。
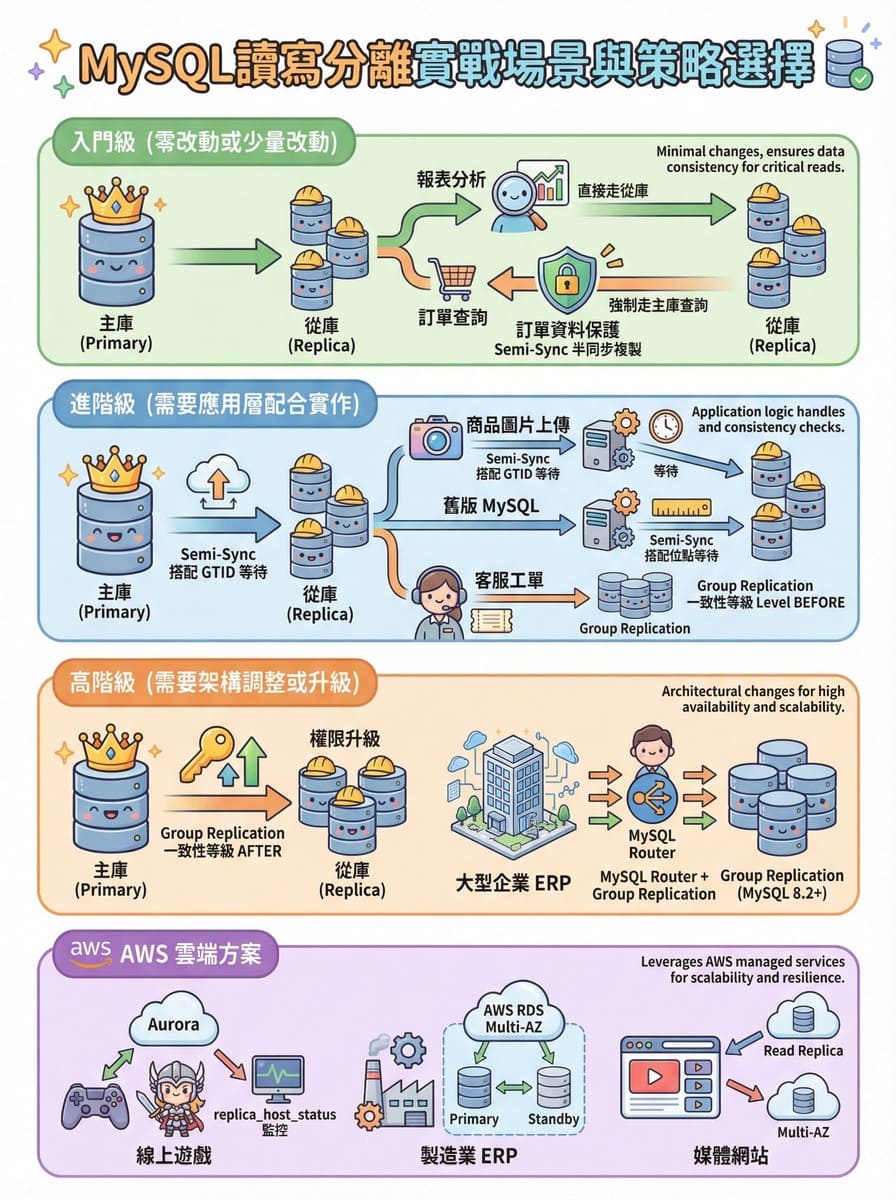
入門級:零改動或少量改動
直接走從庫(不做一致性處理)
| 項目 | 說明 |
|---|---|
| 場景 | 每日/週/月報表,每次需要產出數百萬筆的資料統計,查詢及產出需要耗時 3~5 分鐘 |
| 痛點 | 報表佔用大量資源,若在主庫執行會嚴重影響主庫性能,導致整體用戶體驗下降 |
| 策略 | 一律走從庫,不做任何一致性處理(使用 EVENTUAL) |
優點:不影響主庫效能、程式與架構都簡單實作
缺點:報表資料與即時資料可能會有落差,一般以「歷史資料」來產出
強制走主庫查詢
| 項目 | 說明 |
|---|---|
| 場景 | 用戶在電商平台完成付款後,系統跳轉到「我的訂單」頁面,用戶期望立即看到剛剛下的訂單及付款狀態 |
| 痛點 | 若從從庫讀取可能因同步延遲而顯示「無訂單」,用戶誤以為下單失敗而重複下單,造成客訴和重複扣款 |
| 策略 | 針對特定查詢強制從主庫讀取,不經過從庫 |
優點 1:精確控制哪些查詢需要強一致性
優點 2:實作邏輯簡單
優點 3:100% 保證讀到最新數據
缺點 1:需要判斷哪些場景需要強制主庫
缺點 2:過度使用會失去讀寫分離的意義
缺點 3:增加主庫負擔
Semi-Sync 半同步複製
| 項目 | 說明 |
|---|---|
| 場景 | 線上購物平台的訂單資料庫,用戶完成付款後系統回覆「訂單成立」,必須確保訂單資料已安全存放,即使主庫下一秒斷電也不能丟失 |
| 痛點 | 異步複製下主庫斷電,客戶端已收到「提交成功」但 Binlog 未傳輸到從庫,導致訂單資料永遠丟失 |
| 策略 | 啟用 Semi-Sync,主庫等待至少一個從庫確認收到 Binlog 後才回覆客戶端成功 |
優點 1:配置簡單
優點 2:不需要改變應用程式
優點 3:有效防止資料丟失
優點 4:成本低
缺點 1:網路延遲高或從庫故障時可能退化為異步複製
缺點 2:不提供自動故障轉移
缺點 3:無法解決過期讀問題
進階級:需要應用層配合實作
Semi-Sync 搭配 GTID 等待
| 項目 | 說明 |
|---|---|
| 場景 | 用戶上傳商品圖片後,系統需要取得圖片 ID 並更新商品資料,但圖片記錄剛寫入主庫,從庫可能尚未同步完成 |
| 痛點 | Semi-Sync 只保證 Binlog 傳輸到從庫,但從庫可能尚未執行完成,查詢時仍會發生過期讀導致業務邏輯失敗 |
| 策略 | 寫入後記錄 GTID,讀取從庫前使用 WAIT_FOR_EXECUTED_GTID_SET() 等待從庫執行完成 |
優點 1:精確等待特定交易同步完成
優點 2:可針對單一查詢控制
優點 3:搭配 Semi-Sync 可同時解決資料丟失和過期讀
缺點 1:需要應用層配合實作等待邏輯
缺點 2:從庫延遲大時等待時間長
缺點 3:需要啟用 GTID 模式
Semi-Sync 搭配位點等待
| 項目 | 說明 |
|---|---|
| 場景 | 運行多年的舊版電商系統(MySQL 5.5),無法升級也無法啟用 GTID,但仍需解決用戶修改收貨地址後立即查詢卻看到舊地址的問題 |
| 痛點 | 沒有 GTID 的情況下,無法使用 GTID 等待機制,需要其他方式確保從庫已同步特定交易 |
| 策略 | 寫入後記錄 Binlog 檔案和位點,讀取從庫前使用 MASTER_POS_WAIT() 等待從庫執行到該位點 |
優點 1:不需要 GTID
優點 2:適用於舊版 MySQL
優點 3:原理與 GTID 等待相同
缺點 1:位點管理比 GTID 複雜(需記錄檔案名和位置)
缺點 2:主從切換後位點會變化
缺點 3:應用層實作更繁瑣
Group Replication 一致性等級 BEFORE
| 項目 | 說明 |
|---|---|
| 場景 | 客服系統中,客服人員剛為用戶建立了退款工單,隨即點擊查看工單詳情,系統必須顯示剛建立的工單內容,而非回報「工單不存在」 |
| 痛點 | 從庫查詢時可能讀到過期數據,但不想所有查詢都走主庫增加負擔;手動實作 GTID 等待邏輯太複雜且容易出錯 |
| 策略 | 查詢前設定 group_replication_consistency = 'BEFORE',MySQL 自動等待從庫同步完成後再執行查詢 |
優點 1:MySQL 內部自動處理同步等待邏輯,無需應用層實作
優點 2:可針對 Session 或單次查詢設定
缺點 1:需要 MySQL 8.0.14+ 且啟用 Group Replication
缺點 2:從庫延遲大時查詢會等待較久
高階級:需要架構調整或升級
Group Replication 一致性等級 AFTER
| 項目 | 說明 |
|---|---|
| 場景 | 企業內部系統的管理員修改了某用戶的存取權限(從一般用戶升級為 VIP),修改完成後該用戶無論連到哪個資料庫節點都必須立即擁有 VIP 權限 |
| 痛點 | 主庫更新完成後,連到其他從庫的用戶可能讀到舊的權限資料,造成權限判斷錯誤,用戶明明已升級卻無法使用 VIP 功能 |
| 策略 | 寫入時設定 group_replication_consistency = 'AFTER',交易會等待所有從庫套用完成後才回傳成功 |
優點 1:確保寫入後任何節點都能讀到最新數據
優點 2:適合需要全局一致的配置類更新
缺點 1:寫入延遲明顯增加(需等待所有從庫套用)
缺點 2:不適合高頻寫入場景
MySQL Router + Group Replication(MySQL 8.2+)
| 項目 | 說明 |
|---|---|
| 場景 | 大型企業的 ERP 系統,有數十個微服務連接資料庫,不希望在每個服務中都實作讀寫分離邏輯,也不想在主從切換時逐一修改各服務的資料庫連線設定 |
| 痛點 | 應用程式需要自行判斷讀寫並連接不同端點;主從切換時需要修改所有應用的配置並重新部署,動輒影響數十個服務 |
| 策略 | 使用 MySQL Router 作為代理層,自動識別 SQL 類型並路由到主庫或從庫,搭配 Group Replication 提供高可用 |
優點 1:應用程式只需連接單一端點
優點 2:讀寫路由完全透明
優點 3:主從切換自動處理無需改應用
缺點 1:多一層代理架構
缺點 2:需要額外維護 Router 服務
缺點 3:MySQL 8.2+ 才支援透明讀寫分離
AWS 雲端方案
AWS Aurora + replica_host_status 監控
| 項目 | 說明 |
|---|---|
| 場景 | 線上遊戲公司使用 Aurora 部署了 1 個 Writer 和 5 個 Reader,希望將玩家的查詢請求導向延遲最低的 Reader,以提供最佳的遊戲體驗 |
| 痛點 | Aurora Reader Endpoint 使用輪詢分配連線,可能將請求導向延遲較高的 Reader;無法像傳統 MySQL 用 seconds_behind_master 監控各節點延遲 |
| 策略 | 查詢 information_schema.replica_host_status 取得各 Reader 的 REPLICA_LAG_IN_MILLISECONDS,選擇延遲最低的節點連線 |
優點 1:毫秒級延遲監控精度
優點 2:可實作智能路由選擇最佳節點
優點 3:Aurora 原生支援
缺點 1:需要額外查詢監控表
缺點 2:需要應用層實作選擇邏輯
缺點 3:增加架構複雜度
AWS RDS Multi-AZ
| 項目 | 說明 |
|---|---|
| 場景 | 傳統製造業公司的內部 ERP 系統,使用量不大但資料極為重要,預算有限不想用 Aurora,但仍需要基本的災難恢復能力確保機房故障時系統能繼續運作 |
| 痛點 | 單一 AZ 發生故障(如機房停電、網路中斷)時,資料庫完全無法存取,業務停擺 |
| 策略 | 啟用 RDS Multi-AZ,AWS 自動在另一個 AZ 維護同步備援實例,故障時自動切換 |
優點 1:配置簡單一鍵啟用
優點 2:同步複製確保資料不丟失
優點 3:自動故障轉移
優點 4:無需管理複製邏輯
缺點 1:備援實例不可用於讀取分流(純備援)
缺點 2:成本約加倍
缺點 3:故障轉移時間較長(1-2 分鐘)
AWS RDS Multi-AZ + Read Replica
| 項目 | 說明 |
|---|---|
| 場景 | 媒體網站在 AWS 上運行,文章頁面讀取量極大(讀寫比 100:1),需要擴展讀取能力,同時也需要確保主庫故障時資料不丟失且能自動恢復服務 |
| 痛點 | Multi-AZ 的備援實例不能用於讀取分流;單一主庫無法承受大量讀取請求導致網站變慢 |
| 策略 | 同時啟用 Multi-AZ(高可用)和創建 Read Replica(讀取擴展),分別解決不同問題 |
優點 1:兼具高可用和讀取擴展
優點 2:Read Replica 可跨 AZ 或跨 Region 部署
優點 3:架構靈活
缺點 1:Read Replica 使用異步複製會有延遲
缺點 2:成本較高
缺點 3:需要應用層處理讀寫分離
快速決策表
依一致性需求選擇
| 場景特徵 | 推薦策略 | 一句話理由 |
|---|---|---|
| 報表、分析、歷史數據 | 直接走從庫(EVENTUAL) | 延遲可接受,不影響主庫 |
| 寫入後需要立即讀取 | 強制走主庫 | 最簡單直接,100% 一致 |
| 精確控制一致性(8.0.14+) | GR 一致性等級 BEFORE | MySQL 自動處理等待 |
| 寫入後需要全局可見 | GR 一致性等級 AFTER | 確保所有節點都能讀到 |
| 金融交易、零容忍不一致 | GR BEFORE_AND_AFTER | 最強一致性保證 |
| 舊版 MySQL 需要解決過期讀 | Semi-Sync + GTID/位點等待 | 傳統方案,廣泛適用 |
依環境選擇
| 環境 | 推薦策略 | 一句話理由 |
|---|---|---|
| 自建 MySQL 5.5+ | Semi-Sync | 簡單有效防止資料丟失 |
| 自建 MySQL 8.0.14+ | Group Replication | 強一致 + 自動故障轉移 |
| 自建 MySQL 8.2+ | MySQL Router + GR | 應用層零改動 |
| AWS 新專案 | Aurora | 全托管、低延遲、高可用 |
| AWS 預算有限 | RDS Multi-AZ | 基本高可用保障 |
| AWS 需要讀取擴展 | Aurora 或 RDS + Read Replica | 可水平擴展讀取能力 |
依 MySQL 版本選擇
| MySQL 版本 | 可用的一致性策略 | 可用的資料保護策略 |
|---|---|---|
| 5.5 ~ 5.6 | 強制走主庫、位點等待 | Semi-Sync |
| 5.7 ~ 8.0.13 | 強制走主庫、GTID 等待 | Semi-Sync、基礎 GR |
| 8.0.14 ~ 8.1 | GR 一致性等級(BEFORE/AFTER) | Group Replication |
| 8.2+ | GR 一致性等級 + MySQL Router 透明讀寫分離 | Group Replication + Router |
| AWS Aurora | 強制走主庫、replica_host_status 監控 | Aurora 儲存層自動處理 |
總結
解決「過期讀」問題的關鍵:根據場景選擇適當的一致性等級。
| 問題 | 緊急解 | 長期解 |
|---|---|---|
| 過期讀 | 強制走主庫、Sleep 等待 | GR 一致性等級、GTID 等待 |
| 資料丟失 | Semi-Sync | Group Replication |
| 故障轉移 | 手動切換 | GR + MySQL Router |
延伸閱讀
MySQL 官方文件:
- MySQL 8.0:Semisynchronous Replication
- MySQL 5.7:Semisynchronous Replication
- MySQL 8.0:Group Replication
- Semi-synchronous Replication Performance in MySQL 5.7
Semi-Sync 深入解析:
- Question about Semi-Synchronous Replication: the Answer with All the Details - Percona - 詳細解釋 AFTER_COMMIT vs AFTER_SYNC 的差異與 Phantom Read 問題
- MySQL semi-sync replication: durability, consistency and split brains - PlanetScale - Semi-Sync 的持久性、一致性與腦裂問題
- Improved Semi-Sync Replication in MySQL 5.7 - Datavail - MySQL 5.7 無損複製改進
MySQL Bug 與歷史討論:
- MySQL Bug #62174: A feature for semi-sync replication - 社群對 AFTER_SYNC 功能的討論與貢獻
- MySQL Bug #83158: Phantom-read problem in semi-sync loss-less replication - Phantom Read 問題的 Bug 報告
大規模應用案例:
- Meta Switches to MySQL Raft to Improve Reliability - InfoQ - Facebook 從 Semi-Sync 遷移到 MySQL Raft 的經驗
- Facebook MySQL 5.6 Branch - GitHub - Facebook 維護的 MySQL 分支
AWS 相關: