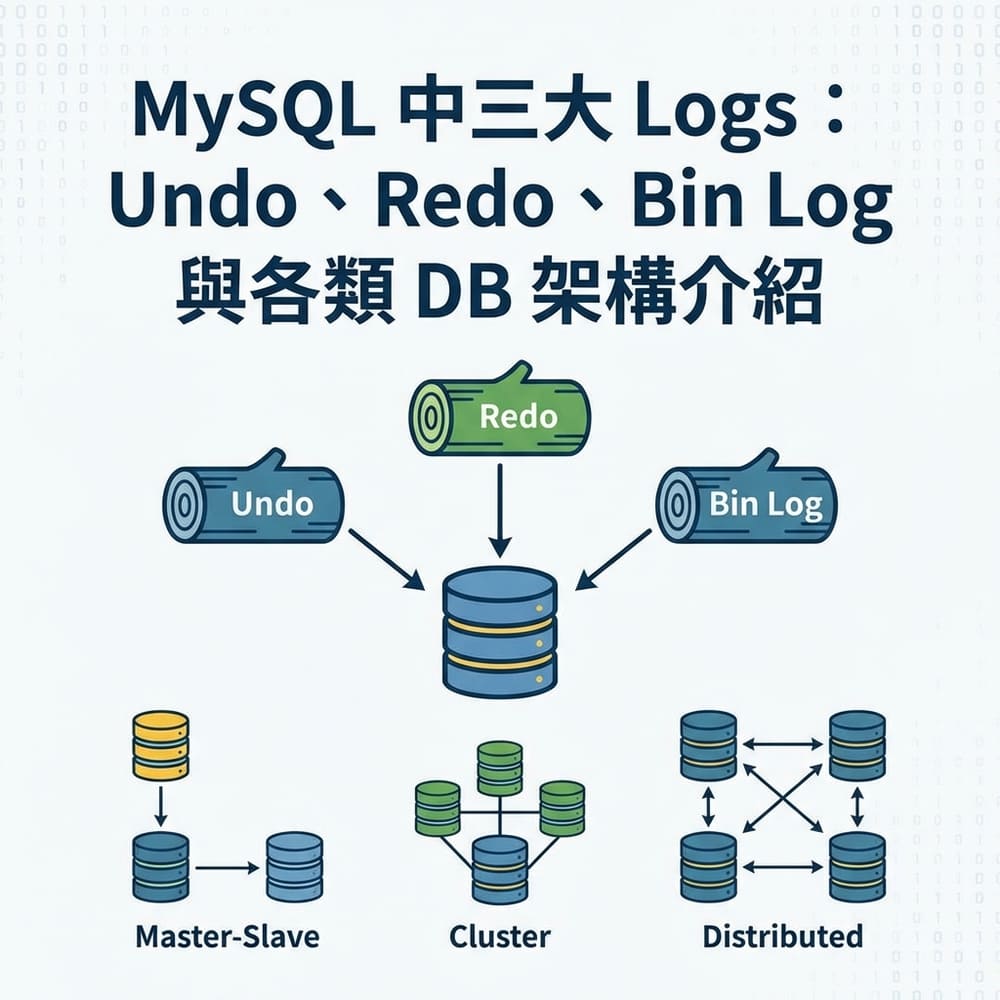
MySQL 中三大 Logs:Undo、Redo、Bin Log 與各類 DB 架構介紹
前言
在 MySQL 中,有三大關鍵的 Log 機制:Undo Log、Redo Log、Bin Log。這三個 Log 分別負責「交易回滾」、「當機恢復」、「主從複製」等核心功能。搞懂它們,就能理解 MySQL 如何保證資料的一致性與持久性!
歌曲
🎵 點擊展開觀看歌曲
三大 Log 一圖流快速理解
情境思考:哪些操作會用到 Log?
思考一下,以下兩個情境分別會用到哪些 Log?
1 | -- 情境 1:SELECT 查詢 |
答案揭曉
SELECT 查詢與 Log 的關係
SELECT 查詢不會寫入任何 Log,但根據隔離級別,可能會讀取 Undo Log 來實現 MVCC(多版本併發控制)。
| Mysql 隔離級別 | 是否讀取 Undo Log | 說明 |
|---|---|---|
| Read Uncommitted | ❌ 不使用 | 直接讀取最新資料,不在乎是否已 Commit |
| Read Committed | ✅ 使用 | 每次查詢都讀取「已 Commit」的最新版本 |
| Repeatable Read | ✅ 使用 | 整個 Transaction 期間讀取「開始時」的快照版本 |
| Serializable | ❌ 不使用 | 透過鎖機制排隊執行,不需要讀取歷史版本 |
重點:SELECT 不會「寫入」Log,但可能「讀取」Undo Log
資料異動(INSERT / UPDATE / DELETE)
當「資料異動時」(Insert、Update、Delete)都會使用到這三個 Log!
三個 Log 的分工如下:
| Log 類型 | 核心目的 | 一句話說明 |
|---|---|---|
| Undo Log | 回滾 + MVCC | Commit 失敗時復原資料,同時支援其他 Transaction 讀取舊版本 |
| Redo Log | 當機恢復 | Server 當機後,透過 Redo Log 恢復已 Commit 但尚未寫入磁碟的資料 |
| Bin Log | 複製 + 備份 | 主從複製的基礎,也用於時間點資料恢復 |
三大 Log 詳解
Undo Log(回滾日誌)
核心目的: Transaction 失敗時的「後悔藥」,同時支援 MVCC 讓其他 Transaction 讀取舊版本資料。
| 項目 | 說明 |
|---|---|
| 目的 | 1. Commit 失敗後復原資料 2. 支援 MVCC,讓其他 Transaction 讀取歷史版本 |
| 記錄內容 | 舊值,例如 score 原本是 60,就記錄 score = 60 |
| 清空時機 | Insert:Commit 後可立即清空 Update/Delete:由 Purge Thread 判斷無 Transaction 需要後才清理 |
| 儲存位置 | Undo Tablespaces(undo_001、undo_002 等檔案) |
為什麼 Insert 和 Update/Delete 的清空時機不同?
1 | Insert:新資料不存在「舊版本」,其他 Transaction 不需要讀取 |
Insert 的 Undo Log:Commit 後立即清空
Update/Delete 的 Undo Log:由 Purge Thread 異步清理,可能保留數小時
Redo Log(重做日誌)
核心目的: 實現 WAL(Write-Ahead Logging)= 先寫日誌再寫資料,確保 Server 當機後資料不丟失。
| 項目 | 說明 |
|---|---|
| 目的 | 避免 Commit 後、資料還沒寫入硬碟時 Server 當機導致資料遺失 |
| 記錄內容 | 記錄「對哪個位置做了什麼修改」(例如:把第 5 頁的第 100 個位置改成 90) |
| 清空時機 | 循環寫入,滿了會從頭覆蓋舊的 Log |
| 儲存位置 | ib_logfile0、ib_logfile1 等檔案 |
WAL 是什麼?為什麼需要 Redo Log?
WAL = Write-Ahead Logging = 先寫日誌再寫資料
1 | 【沒有 Redo Log 的問題】 |
Redo Log 將「隨機寫入」轉換為「順序寫入」,提升效能
當機重啟後 MySQL 會自動透過 Redo Log 恢復資料
Bin Log(二進位日誌)
核心目的: 主從複製的基礎,也用於時間點資料恢復(Point-in-Time Recovery)。
| 項目 | 說明 |
|---|---|
| 目的 | 1. 主從複製(讀寫分離) 2. 時間點資料恢復 |
| 記錄內容 | 記錄 SQL 語句或每一列的變化(取決於設定) |
| 清空時機 | 不清空!追加寫入,檔案滿了換新檔案 |
| 儲存位置 | mysql-bin.000001、mysql-bin.000002… |
Redo Log vs Bin Log 差異
| 項目 | Redo Log | Bin Log |
|---|---|---|
| 層級 | InnoDB 引擎層 | MySQL Server 層 |
| 記錄類型 | 記錄「頁面哪裡改了什麼」 | 記錄「SQL 語句或資料變化」 |
| 用途 | 當機恢復(MySQL 重啟時自動讀取並恢復) | 主從複製 + 時間點恢復(需 DBA 手動執行 mysqlbinlog 指令) |
| 寫入時機 | Transaction 執行中持續寫入 | Commit 時一次寫入 |
| 生命週期 | 循環覆蓋 | 持續追加 |
Redo Log:InnoDB 的「保險箱」,保護單機資料
Bin Log:MySQL 的「日記本」,支援複製與備份
三大 Log 能否被關閉?
重要觀念: 並非所有 Log 都可以被設定開關!
| Log 類型 | 能否關閉 | 說明 |
|---|---|---|
| Undo Log | ❌ 無法關閉 | InnoDB 核心機制,Transaction 回滾與 MVCC 必須依賴它 |
| Redo Log | ❌ 無法關閉 | InnoDB 核心機制,WAL 策略與當機恢復必須依賴它 |
| Bin Log | ✅ 可以關閉 | 透過 log_bin 參數設定開關(預設在 MySQL 8.0+ 為開啟) |
1 | -- 查看 Bin Log 是否開啟 |
為什麼只有 Bin Log 可以關閉?
- Undo Log / Redo Log:屬於 InnoDB 儲存引擎層,是保證 ACID 特性的核心機制,關閉會破壞資料一致性
- Bin Log:屬於 MySQL Server 層,主要用於主從複製與備份,單機環境下不需要複製功能時可以關閉
MySQL 完整架構圖
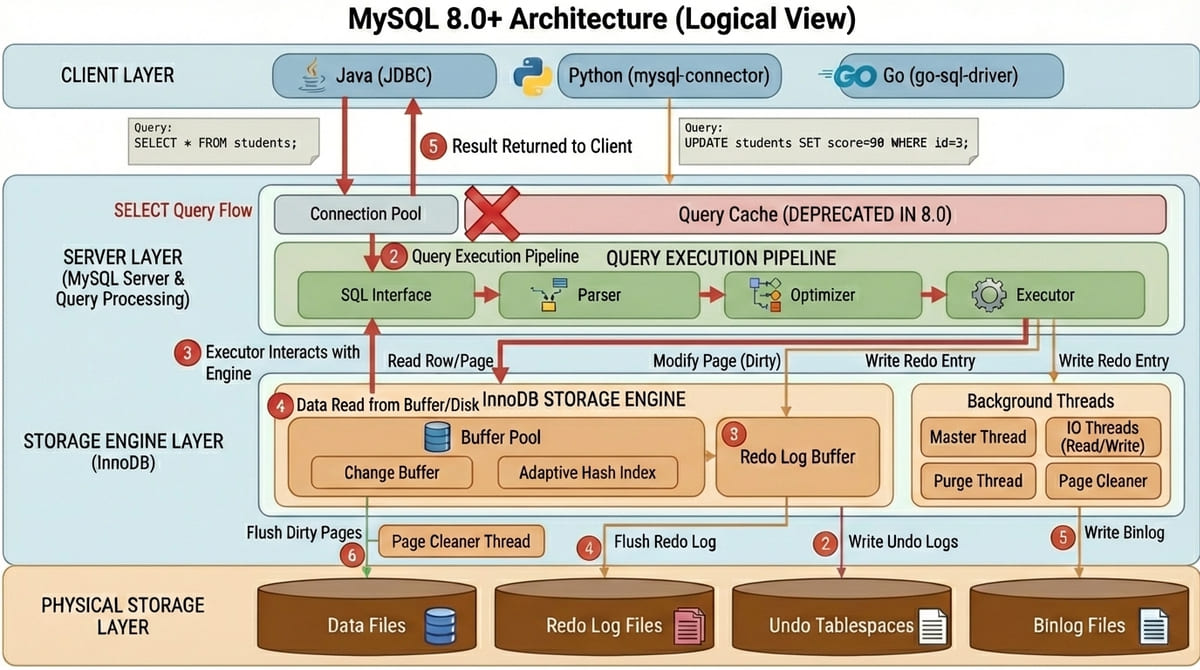
架構圖中的其他知識點補充
Change Buffer
目的: 減少 Disk I/O,針對非唯一索引的寫入進行優化。
| 項目 | 說明 |
|---|---|
| 對象 | Non-Unique 的 Secondary Index |
| 原理 | 將變更先暫存在 Buffer,之後再批次合併寫入 |
| 預設狀態 | MySQL 5.5~8.3:開啟 MySQL 8.4:關閉 MySQL 9.0+:開啟 |
| 適用時機 | HDD 環境下效益較大,SSD 環境可考慮關閉 |
什麼是非唯一索引(Non-Unique Index)?
索引類型分類:
- 唯一索引(Unique Index):包含 Primary Key 與 Unique Key,確保欄位值不重複
- 非唯一索引(Non-Unique Index):一般的 Secondary Index,允許欄位值重複
延伸思考:為什麼只有「非唯一索引」才能使用 Change Buffer?
核心原因: 唯一性檢查需要立即讀取資料頁,無法延遲寫入。
1 | 【唯一索引的寫入流程】 |
非唯一索引:可延遲寫入,減少 Disk I/O
唯一索引:必須立即檢查,無法使用 Change Buffer
Background Threads
目的: 職責拆分,適應高併發場景。
| Thread 類型 | 職責 |
|---|---|
| IO Threads | 處理讀寫 I/O 請求 |
| Purge Thread | 清理已不需要的 Undo Log |
| Page Cleaner | 將修改過的資料寫入硬碟 |
| Log Writer | 將 Redo Log 從記憶體寫入硬碟 |
1 | -- 查看當前 Thread 設定 |
範例輸出:
| Variable | Value |
|---|---|
| innodb_ddl_threads | 4 |
| innodb_log_writer_threads | ON |
| innodb_parallel_read_threads | 4 |
| innodb_purge_threads | 1 |
| innodb_read_io_threads | 5 |
| innodb_write_io_threads | 4 |
Log Buffer 監控指令
1 | -- ========== Binlog Buffer ========== |
調優建議:
- 如果
Binlog_cache_disk_use很高 → 增加binlog_cache_size - 如果
Innodb_log_waits很高 → 增加innodb_log_buffer_size
Adaptive Hash Index(AHI)
目的: 透過 Hash Map 加速熱點資料的查詢。
| 項目 | 說明 |
|---|---|
| 原理 | MySQL 自動為頻繁查詢的資料建立 Hash 索引 |
| 預設狀態 | MySQL 8.0:開啟 MySQL 8.4+:關閉 |
| 適用場景 | 有明顯熱點資料的 OLTP 場景 |
1 | -- 查看 AHI 狀態 |
延伸比較:其他資料庫的 Log 機制
了解 MySQL 的三大 Log 後,我們來看看其他資料庫是如何設計的。
PostgreSQL:單一 WAL 取代三大 Log
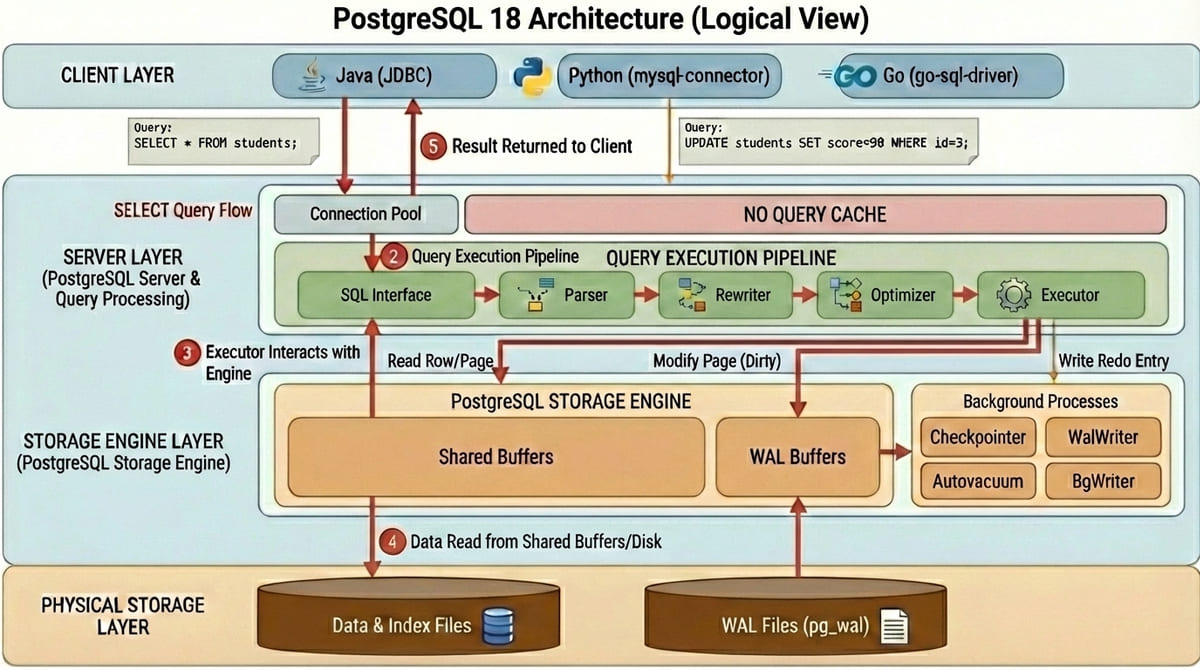
PostgreSQL 沒有 Undo Log、Redo Log、Bin Log! 它使用單一的 WAL(Write-Ahead Log) 來處理所有功能。
| 項目 | MySQL | PostgreSQL |
|---|---|---|
| 回滾機制 | Undo Log | WAL + MVCC(舊版本保留在原表) |
| 當機恢復 | Redo Log | WAL |
| 複製機制 | Bin Log | WAL |
| 連線模型 | 多線程(Thread) | 多進程(Process) |
| 緩存管理 | Buffer Pool(InnoDB 獨立管理) | Shared Buffer(與 OS 共同管理) |
MySQL vs PostgreSQL 的 Thread/Process 差異
MySQL 的風險: 如果某個 Thread 因為爛 SQL 導致記憶體飆升,觸發 OS OOM Killer(Linux),整個 MySQL Process 會被終止,影響所有連線。
PostgreSQL 的優勢: 每個連線是獨立 Process,單一連線出問題不會影響其他連線,但代價是資源消耗較高。
Redis:NoSQL 緩存的標配首選
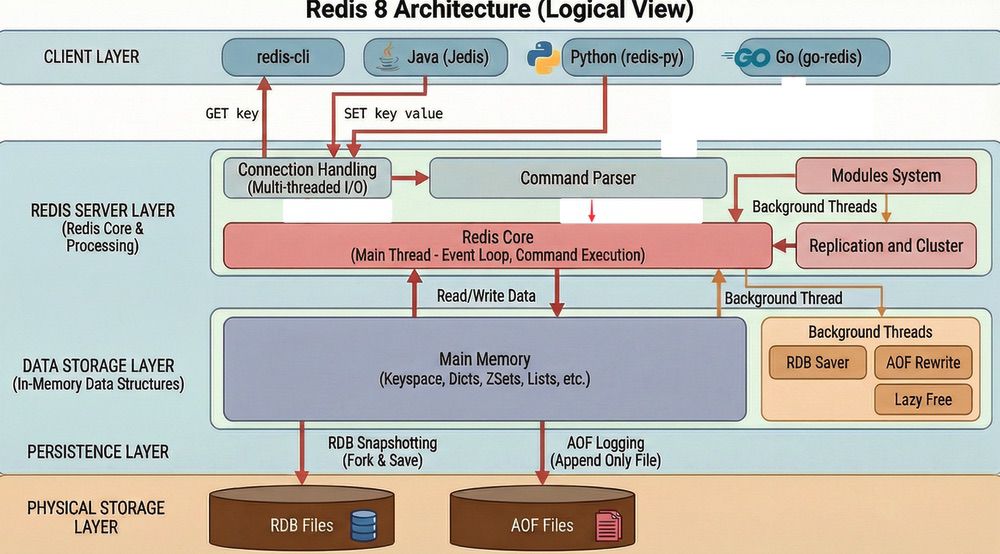
Redis 是現代應用中最常見的緩存解決方案,資料儲存在記憶體。
| 項目 | MySQL(OLTP) | Redis(Cache) |
|---|---|---|
| 主要儲存位置 | 硬碟(Disk) | 記憶體(Memory) |
| 讀寫速度 | 毫秒級(ms) | 微秒級(μs) |
| 持久化機制 | Redo Log 確保 Commit 後資料不丟失 | RDB 快照 + AOF 日誌(7.0+ 預設啟用) |
| 適合場景 | 持久化業務資料 | 高頻讀取的熱點資料緩存 |
為什麼 Redis 這麼快?
核心原因: 記憶體的讀寫速度是硬碟的 10 萬倍以上!
1 | 【不同儲存媒介的讀取速度比較】 |
Redis 將資料存在記憶體,讀取延遲僅需 ~100 ns
傳統 HDD 讀取需要 ~10 ms,差距高達 10 萬倍
Redis 的執行緒模型
常見誤解: 「Redis 是單執行緒」——這個說法只對一半!
| 版本 | 執行模型 | 說明 |
|---|---|---|
| Redis < 6.0 | 純單執行緒 | 網路 I/O 和命令執行都在同一個執行緒 |
| Redis ≥ 6.0 | 多執行緒 I/O | 網路 I/O 改用多執行緒處理,命令執行仍是單執行緒 |
1 | 【Redis 6.0+ 執行緒模型】 |
命令執行單執行緒:不需要 Lock,避免競爭條件(Race Condition)
網路 I/O 多執行緒:提升高併發場景下的吞吐量
Redis 的持久化機制:RDB vs AOF
相較於 MySQL 的三大 Log,Redis 使用 RDB 和 AOF 兩種機制來解決「當機後資料恢復」的問題。
RDB(Redis Database)
原理: 定期將 Redis 記憶體中的資料「拍快照」,完整寫入 .rdb 檔案。
1 | 【RDB 運作流程】 |
| 項目 | 說明 |
|---|---|
| 檔案格式 | 二進位壓縮格式(.rdb) |
| 觸發方式 | 手動執行 SAVE/BGSAVE 指令,或在 redis.conf 設定條件自動觸發(如 save 900 1 表示 900 秒內有 1 次寫入就觸發) |
| 還原速度 | 快(直接載入快照) |
SAVE vs BGSAVE 差異
| 指令 | 執行方式 | 說明 |
|---|---|---|
SAVE | 同步(阻塞) | Redis 主執行緒直接執行快照,期間無法處理任何請求 |
BGSAVE | 背景(非阻塞) | Fork 一個子進程來執行快照,主執行緒繼續處理請求 |
1 | 【SAVE 的問題】 |
生產環境幾乎都用 BGSAVE,避免服務中斷。SAVE 只適合在維護時段或測試環境使用。
什麼是 Fork?
fork() 是 Linux/Unix 的系統呼叫,用來「複製」當前進程,產生一個幾乎一模一樣的子進程。子進程會繼承父進程當下的記憶體狀態。
為什麼 BGSAVE 要用「子進程」而不是「新執行緒」?
- 執行緒共享記憶體,寫入快照時若主執行緒修改資料,會導致快照內容不一致
- 子進程透過 Copy-on-Write(寫時複製) 機制,取得當下記憶體的「快照副本」,不受主進程後續修改影響
優點 1:儲存完整快照,適合備份與災難恢復
優點 2:還原速度快,適合大量資料恢復
缺點 1:兩次快照之間若當機,中間的資料會遺失
缺點 2:Fork 子進程時需複製記憶體頁表,資料量大時會消耗 CPU 並造成短暫卡頓
AOF(Append-Only File)
原理: 每次執行寫入命令(SET、DEL 等),都追加記錄到 .aof 日誌檔案。
1 | 【AOF 運作流程】 |
| 項目 | 說明 |
|---|---|
| 檔案格式 | 純文字格式(.aof),可直接 cat 查看 |
| 同步策略 | always(每條命令)/ everysec(每秒)/ no(由 OS 決定) |
| 還原速度 | 較慢(需逐行重播命令) |
AOF 同步策略設定
在 redis.conf 中透過 appendfsync 參數設定:
1 | # redis.conf |
| 策略 | 資料安全性 | 效能 | 說明 |
|---|---|---|---|
always | ⭐⭐⭐ 最高 | 最慢 | 每條命令都 fsync,最多丟失 1 條命令 |
everysec | ⭐⭐ 中等 | 平衡 | 每秒 fsync 一次,最多丟失 1 秒資料(推薦) |
no | ⭐ 最低 | 最快 | 由 OS 決定(通常 30 秒),可能丟失大量資料 |
生產環境推薦使用 everysec:在效能與資料安全之間取得平衡,最多只會丟失 1 秒內的資料。
優點 1:資料幾乎不遺失(設定 always 可確保每條命令都記錄)
優點 2:純文字格式,方便 Debug 和人工檢視
缺點 1:檔案比 RDB 大(記錄每一條命令)
缺點 2:還原速度較慢(需逐行執行命令)
RDB + AOF 混合持久化
Redis 4.0+ 推薦做法: 結合 RDB 和 AOF 的優點,這也是目前商業環境的主流配置。
1 | 【混合持久化運作原理】 |
| 對比項目 | 純 RDB | 純 AOF | 混合模式 |
|---|---|---|---|
| 資料完整性 | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 還原速度 | ⭐⭐⭐ | ⭐ | ⭐⭐⭐ |
| 檔案大小 | ⭐⭐⭐ | ⭐ | ⭐⭐ |
混合模式結合兩者優點:還原快 + 資料完整
Redis vs MySQL 持久化機制對比
| 項目 | MySQL | Redis |
|---|---|---|
| 當機恢復 | Redo Log(WAL) | RDB / AOF |
| 交易回滾 | Undo Log | ❌ 不支援(無 Transaction 概念) |
| 主從複製 | Bin Log | RDB 傳輸 + 命令同步 |
| 資料保證 | ACID | 最終一致性 |
MongoDB:可持久化的 NoSQL 資料庫
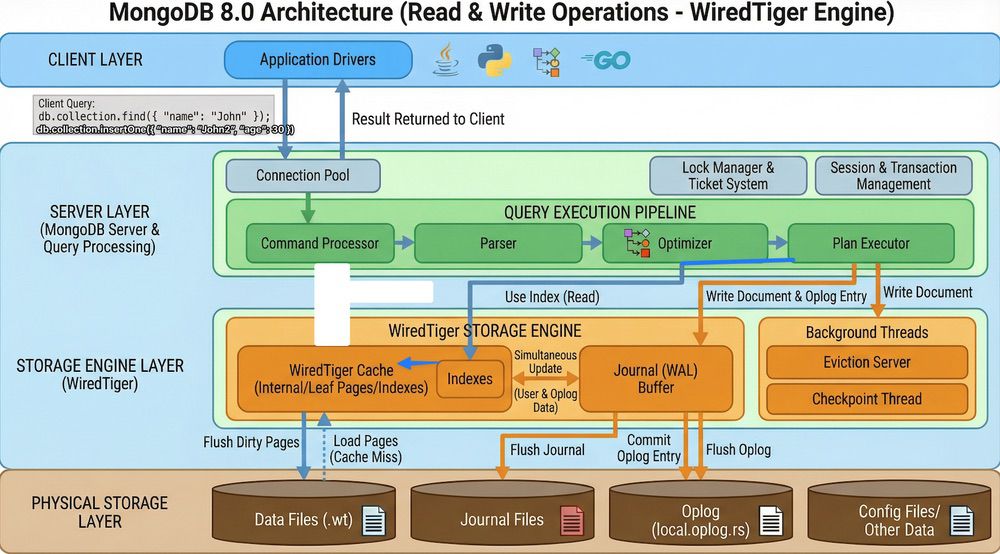
MongoDB 是一個 Document-based 的 NoSQL 資料庫,兼具「彈性 Schema」與「持久化儲存」的特性,適合快速迭代或者記憶體有限 Server 時候要做緩存資料的首選。
| 項目 | MySQL(OLTP) | MongoDB(Document DB) |
|---|---|---|
| 資料模型 | 關聯式表格(Row) | 文件(Document / JSON) |
| Schema | 固定欄位,需 ALTER TABLE | 彈性 Schema,可隨時新增欄位 |
| 儲存位置 | 硬碟 + Buffer Pool 快取 | 硬碟 + WiredTiger Cache(另有純記憶體引擎可選) |
| 適合場景 | 強一致性交易、複雜 JOIN | 快速開發、彈性資料結構、大量讀寫 |
關於「純記憶體引擎」的說明:
- MySQL 和 MongoDB 預設都是硬碟儲存 + 記憶體快取(MySQL 用 Buffer Pool,MongoDB 用 WiredTiger Cache)
- MongoDB 額外提供 In-Memory Storage Engine,這是一個完全不寫硬碟的儲存引擎,所有資料只存在記憶體中(等同於實作 Redis)
- 純記憶體引擎適合:Session 管理、即時快取、臨時運算等可接受資料遺失的場景
- 重啟後資料會全部消失,因此不適合需要持久化的業務資料
如何啟用 MongoDB In-Memory Storage Engine:
1 | # 啟動時指定使用純記憶體引擎 |
注意事項:
- In-Memory Engine 僅在 MongoDB Enterprise 版本提供
MongoDB 的 Log 機制
MongoDB 使用 Journal 和 Oplog 兩種 Log,功能與 MySQL 的 Redo Log 和 Bin Log 類似。
| Log 類型 | 功能 | 對應 MySQL |
|---|---|---|
| Journal | 當機恢復(WAL 機制) | Redo Log |
| Oplog | 主從複製(操作日誌) | Bin Log |
1 | 【MongoDB 寫入流程】 |
Journal:類似 MySQL 的 Redo Log,實現 WAL 機制保護資料
Oplog:類似 MySQL 的 Bin Log,記錄所有操作供 Replica Set 同步
為什麼選擇 MongoDB?
彈性 Schema:隨時新增欄位
傳統 MySQL 痛點: 新增欄位需要 ALTER TABLE,大表可能鎖表數小時。
MongoDB 解法: Document 結構天生支援彈性欄位,無需 Migration。
1 | // MongoDB:同一個 Collection 中,Document 結構可以不同 |
優點:快速迭代,適合敏捷開發
缺點:缺乏 Schema 約束,資料一致性需靠應用層保證
儲存在硬碟:比 Redis 更經濟
Redis vs MongoDB 的定位差異: Redis 是「記憶體緩存」,MongoDB 是「持久化資料庫」。
| 對比項目 | Redis | MongoDB |
|---|---|---|
| 資料儲存位置 | 記憶體(RAM) | 硬碟(Disk) |
| 成本 | 高(記憶體貴) | 低(硬碟便宜) |
| 資料量上限 | 受記憶體限制 | 可儲存 TB 級資料 |
| 適合場景 | 熱點資料緩存 | 主要資料儲存 |
1 | 【成本估算範例 - 2026 AWS Tokyo 區域】 |
MongoDB 適合:需要持久化、資料量大、預算有限的場景
Redis 適合:高頻讀取的熱點資料、Session 緩存、排行榜
原生分片:輕鬆水平擴展
MongoDB 原生支援 Sharding(分片),可以輕鬆將資料分散到多個節點。
1 | 【MongoDB Sharding 架構】 |
名詞定義
- 讀寫分離:一主多從,擴展「讀取」能力(MySQL 內建支援)
- Sharding:資料分散到多個獨立資料庫,擴展「寫入」能力與儲存容量
當單一主庫遇到寫入瓶頸或資料量超過單機上限時,讀寫分離無法解決,需要 Sharding。
| 對比項目 | MySQL | MongoDB |
|---|---|---|
| 讀寫分離 | ✅ 內建支援 | ✅ Replica Set |
| Sharding(水平擴展) | ❌ 需額外工具(Vitess、ShardingSphere) | ✅ 原生支援 |
| 設定複雜度 | Sharding 需要高 | 中 |
| 自動 Rebalance | ❌ | ✅ |
什麼是 Rebalance(資料再平衡)?
當某個 Shard 資料量過大或新增節點時,系統自動將部分資料搬移到其他節點,確保負載均勻分佈。MongoDB 內建此功能,MySQL Sharding 方案通常需要手動處理。
原生 Sharding 支援,無需第三方工具
自動資料平衡,新增節點後自動遷移資料
ClickHouse:OLAP 資料庫的不同設計
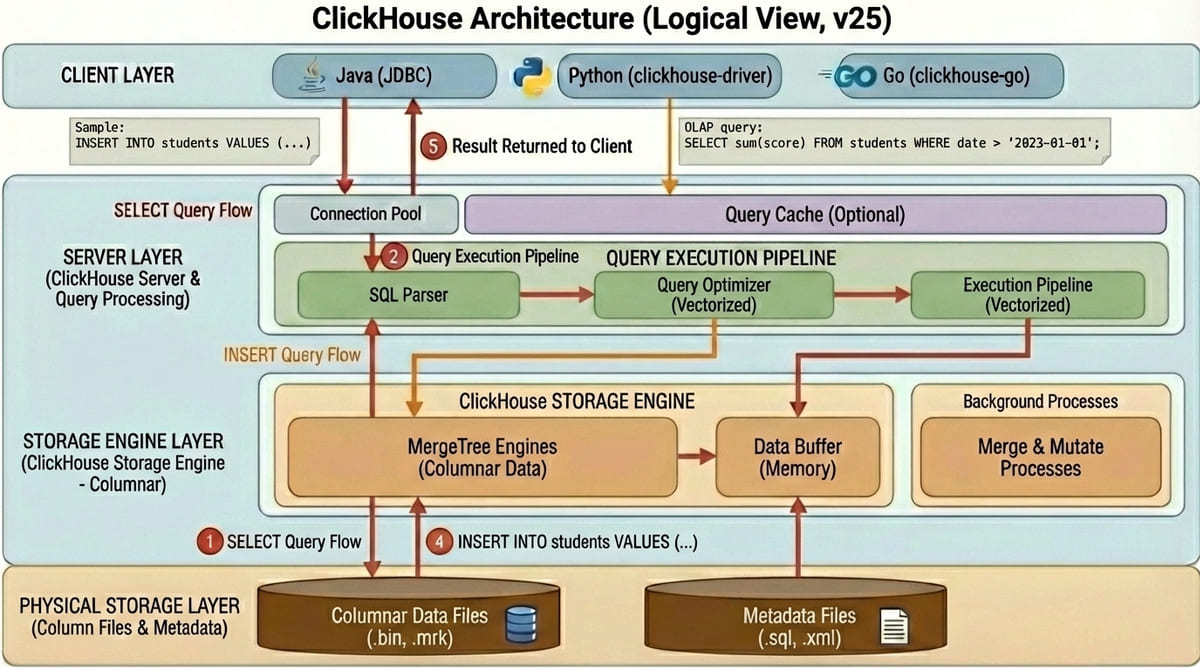
ClickHouse 是 OLAP 資料庫,設計理念與 OLTP(MySQL、PostgreSQL)完全不同。
| 項目 | MySQL(OLTP) | ClickHouse(OLAP) |
|---|---|---|
| 儲存方式 | Row-based | Column-based |
| 適合場景 | 高併發小查詢 | 海量資料分析 |
| Query Cache | 8.0 後移除 | 有(v23.1+,預設關閉) |
| 執行方式 | 一個連線 = 一個 Thread | ⚠️(需要特別注意)一個 SQL = 所有 CPU 一起處理 |
| 寫入方式 | 直接寫入指定位置 | 先寫臨時區,背景 Merge |
ClickHouse 的核心特點
Column-based 儲存:分析查詢只需讀取相關欄位,速度極快
Vectorized 執行:批次處理資料,大幅提升運算效率
MergeTree 引擎:寫入先暫存,背景合併,避免隨機 I/O
不適合高併發:一個查詢會佔用所有 CPU
不適合頻繁更新:設計上偏向「追加寫入」
Milvus:向量資料庫的架構
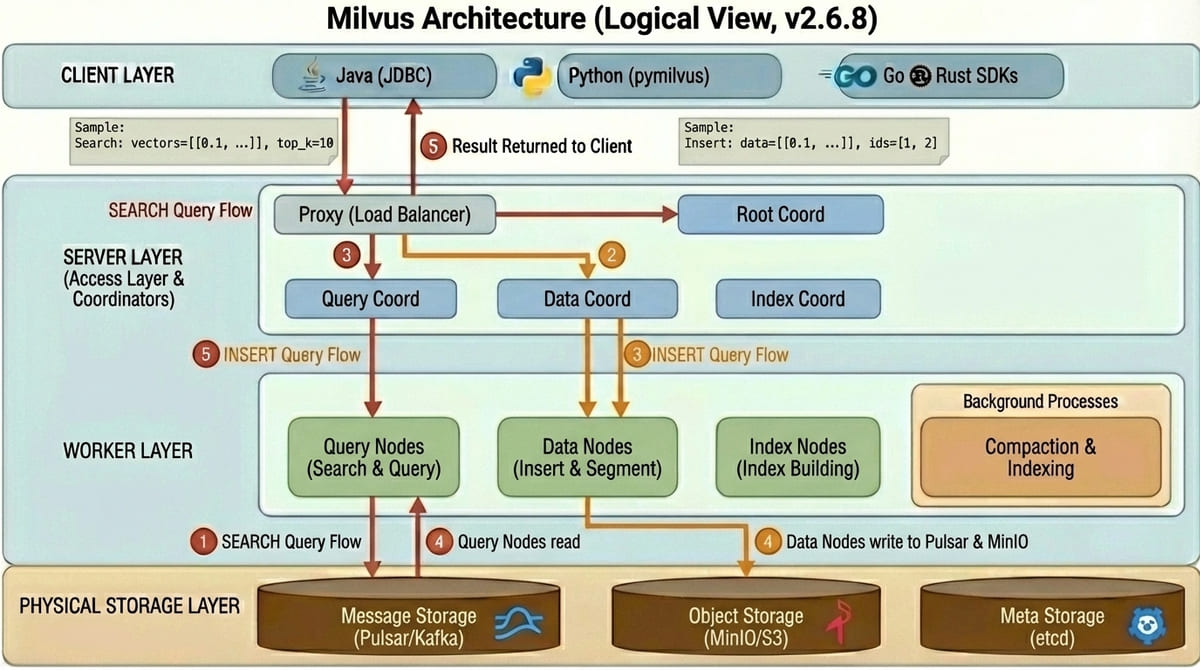
Milvus 是向量資料庫,專門處理 AI Embedding 的相似度搜尋,與傳統資料庫的設計完全不同。
| 項目 | MySQL(OLTP) | Milvus(Vector DB) |
|---|---|---|
| 查詢方式 | 精確查詢(WHERE id = 3) | 相似度查詢(找最像的 Top K) |
| 索引類型 | B+ Tree、Hash | IVF_FLAT、HNSW 等向量索引 |
| 比對方式 | 值是否相等 | 向量距離(計算相似程度) |
| 適合場景 | 電商訂單、用戶資料 | 推薦系統、語意搜尋、RAG |
常見向量距離算法:
- 歐式距離(L2):計算兩點間的直線距離,適合絕對位置相似度比較
- 內積(IP):計算向量夾角的餘弦值乘以長度,適合推薦系統
- 餘弦相似度(Cosine):只看方向不看長度,適合文字語意比較
思考:假設使用 MySQL 儲存向量,程式端需自行實作相似度計算,可行嗎?
1 | // PHP + Laravel 為例 |
可行,但是這種做法會產生以下問題:
- CPU 負擔大:每次查詢都要對所有資料計算相似度
- 網路頻寬大:需將所有向量資料從 DB 傳到應用層
- 效能低落:無法利用索引,時間複雜度為 O(n)(為什麼失效,請具體查看下面的「為什麼向量資料庫不能用 B+ Tree?」
延伸思考:為什麼向量資料庫不能用 B+ Tree?
維度災難(Curse of Dimensionality): 向量通常是 768 維甚至更高,傳統索引在高維空間下完全失效。
舉例來說,一個句子經過 Embedding 模型轉換後,會變成這樣的向量:
1 | "今天天氣很好" → [0.123, -0.456, 0.789, 0.234, ..., -0.567] // 共 768 個維度 |
B+ Tree 的排序邏輯是「單一維度比大小」,但向量有 768 個維度,無法決定誰大誰小:
| 向量 A | 向量 B | 誰比較大? |
|---|---|---|
[0.1, 0.9, ...] | [0.8, 0.2, ...] | 第一維 B 大,第二維 A 大,無法排序 |
因此向量資料庫必須使用專門的索引結構(如 HNSW、IVF),透過「近似最近鄰搜尋(ANN)」來快速找到相似向量。
應用場景對照表
1 | ┌──────────────────┬──────────────────────────────────────────────────┐ |
總結
三大 Log 的核心價值:
- Undo Log:交易的「後悔藥」+ MVCC 的基礎
- Redo Log:當機恢復的「保險箱」(WAL 策略)
- Bin Log:主從複製的「傳輸帶」+ 時間點恢復的「時光機」
| Log 類型 | 一句話總結 |
|---|---|
| Undo Log | Commit 失敗能回滾,其他 Transaction 能讀舊版本 |
| Redo Log | 先寫 Log 再寫資料,當機後能恢復 |
| Bin Log | 主從複製靠它傳資料,備份恢復靠它回到過去 |
延伸閱讀
MySQL 官方文件:
相關文章: